Just Dictation
How a $25 indie Mac app replaced my keyboard. No subscription, no voice OS required. I started experimenting with dictation on macOS last summer. Apple's native dictation had been bothering me for a while, and ChatGPT's in-app version made it pretty clear the underlying tech was well ahead of what Apple was shipping. I'd done some Automatic Speech Recognition (ASR) benchmarking at Amazon a few years back, which lined up with what I was seeing: state-of-the-art was moving quickly, and OS-native dictation wasn't keeping up. So I started looking around. Like most people, I evaluated Wispr Flow and the other popular Mac dictation apps before landing on VoiceInk. For most of the year, I used it sporadically and was happy enough with it. About a month ago, that changed, and my usage went up sharply. So much so that at this point I'm officially, completely voice-pilled. And I'm glad I picked VoiceInk when I did. This post walks through my current setup and the choices behind each decision. And my claim on the bigger picture: we're at an inflection point where the keyboard is on its way out as the default way we talk to our computers. After forty years of typing, this is one of the most consequential shifts I've watched happen in personal computing. In one sentence: I press the keyboard shortcut, audio goes from my mic into VoiceInk, which hands it off to From the moment I stop talking, the cleaned-up text lands on screen in one to two seconds, and that latency stays roughly constant whether I dictated a sentence or a full paragraph (more on this in the next section). Accuracy is high enough that I'm correcting maybe a word or two per ten sentences after the Gemini pass. That combination flipped the keyboard/voice usage ratio for me. I used to write something about 90% using the keyboard and 10% by dictation; today it's essentially the inverse of that. Conversational English runs around 150 to 170 words per minute, while average typing on a desktop keyboard sits closer to 52 wpm. Roughly 3× the bandwidth, which is enough that going back to the keyboard for general prose feels like I'd be insisting on communicating through Morse code. And speed is only half of the appeal. The friction of typing carries a quiet cognitive cost for the small stuff (a quick Slack reply, a half-formed thought, a two-sentence question), and dictation drops it to zero. A chunk of what I now write would have stayed in my head. Three things got significantly better for me in the past month or so. Start with transcription. Last summer I was running a quantized Whisper locally through Ollama; nice for privacy, but accuracy wasn't good enough. So I graduated to Groq inference running the same model unquantized. That worked well for a while, until Groq's latency crept up enough that I started reaching for the dictation shortcut less. I then tried a handful of services and settled on ElevenLabs' Scribe v2 Realtime, which shipped late last year. The big jump with Scribe v2 Realtime was not so much accuracy (it is slightly better) as the streaming architecture, which I was using for the first time. It transcribes the audio while I'm still talking, instead of waiting for the file to close before it starts. With file-based ASR, end-to-end latency is The second piece is enhancement: a second pass VoiceInk runs on the raw transcript to clean up disfluencies, smooth phrasing, and apply a custom prompt (which I'll also get to). The model that landed for me here was Gemini 3.1 Flash-Lite, the cheapest and fastest tier in Google's current lineup. Smart enough to follow a multi-clause prompt and adds about 1 to 1.5 seconds on average, which hits the sweet spot for me on the accuracy/latency curve. The mic upgrade is the third piece. Modern speech-to-text models are built to hold up under degraded audio (think telephony use cases), but the accuracy drop is never really zero. If you can afford to pay ~$100 to clean up your input, you should (and your Zoom guests will appreciate). A few weeks ago I switched from the mic embedded in my old Sony XM3 headphones to a Sennheiser Profile USB cardioid condenser, and the output quality improved noticeably. As far as I can tell, VoiceInk is a one-developer macOS app by Prakash Joshi Pax. It doesn't do much marketing, and I landed on it the usual way, by searching around and asking Claude. The source is on GitHub under GPL v3, so you can clone it and build it yourself for free. The paid license is $25 for one Mac (or $49 for the multi-Mac tier) and goes directly to the developer. The app ships updates every couple of weeks and is already as feature-rich as I need (custom dictionaries, trigger words that route to different custom prompts, voice activity detection, to name a few). It's also BYOK: you bring your own API keys for the models you use. I run the paid build because I want the updates, yes, but also it'd feel wrong not to support the work. The pricing model is what sold me initially. One-time fee, no subscription. I was a fan of DHH's Once philosophy from a couple of years ago, and I don't see how a subscription is defensible in this space. The underlying models keep getting better and cheaper every quarter; charging a recurring fee for the interface on top while taking away the user's choice of which models run doesn't add up. BYOK may sound like extra cost and friction, but in practice it's neither. My Gemini bill comes out to under 10 cents a month, and ElevenLabs runs me roughly $3 a month at daily-use volume. The real payoff of holding the keys, though, is the freedom to swap. I've already moved VoiceInk's transcription provider three times this past year (local Whisper, then Groq, now ElevenLabs), without ever waiting on the app to catch up to whatever had shipped most recently. The other thing you get with VoiceInk is a developer you can reach. When VoiceInk's "pause media while recording" feature (pauses Spotify and the like while you're speaking and resumes after) misbehaved on my setup, I filed an issue on Github and it was fixed quickly. When OpenAI's realtime Whisper shipped last week and VoiceInk didn't yet support it, I opened another issue on the repo and expect it to be resolved any day. That kind of turnaround is harder to get once a product serves millions and is owned by a large team with a multi-year roadmap and a board (though a one-person shop has bottlenecks of its own, granted). Wispr Flow has raised $81M to build a "voice operating system," which is a different bet on a different timeline. For what dictation actually is today, though, I honestly don't see what $10 to $15 a month for a subscription buys me over $25 once plus a few dollars a month in API fees. Though at this point, calling VoiceInk dictation software is already too small a word. Take the trigger words. I have one mapped to "assistant": when a dictation starts with the word, VoiceInk routes the transcript to a different prompt that tells Gemini to answer the question rather than transcribe it. So "assistant, what is the time difference between London and Tokyo?" pastes the answer where my cursor sits, no chat window or copy-paste round trip. The dictation shortcut doubles as a one-shot LLM shortcut. Or the custom prompt that handles most of my utterances. One line: "If my dictation ends with 'Fix my rambling,' treat everything before it as a rough draft and return a streamlined version of what I meant." When the output isn't tight enough, I tack on "fix my rambling" and the model rewrites its first pass into something closer to what I would have typed if I'd taken the time. Another line, added last week: "If my dictation ends with 'in LaTeX,' write the math in LaTeX surrounded by $." So "sum from i equals zero to n of x sub i, in LaTeX" pastes Or the multilingual capture. The transcription model figures out which of English, French, and Japanese I'm speaking on its own. My keyboard can only print one layout and the other two live in muscle memory, whereas dictating skips the layout entirely. It's not all there yet. One rough patch I keep hitting is the long tail of names and acronyms specific to my world. VoiceInk has a custom dictionary, but I have to populate it word by word, and what I'd want is for the app to flag the words it likely didn't understand and let me confirm them in a batch later. Then there's latency. One to two seconds is great, don't get me wrong, but it's not yet fast enough that I stop noticing the wait. I expect the remaining latency and accuracy gaps to close fast, and dictation to fold into a bigger category whose name is still up for grabs (Voice AI, Voice computing?). The whole stack is on a steepening curve. Two demos from the past couple of weeks hint at what might come next: OpenAI's gpt-realtime-1.5 controlling an app's UI by voice, and Google DeepMind's Gemini-powered pointer driven by motion and speech. As with everything in AI right now, a helpful reminder is that what we're using today is the worst version we'll ever use. And that's already really good.
My Setup
ElevenLabs Scribe v2 Realtime for transcription, then runs the result through Gemini 3.1 Flash-Lite with a short custom prompt, and pastes the cleaned-up text into whatever app is in front of me. Four layers, one shortcut.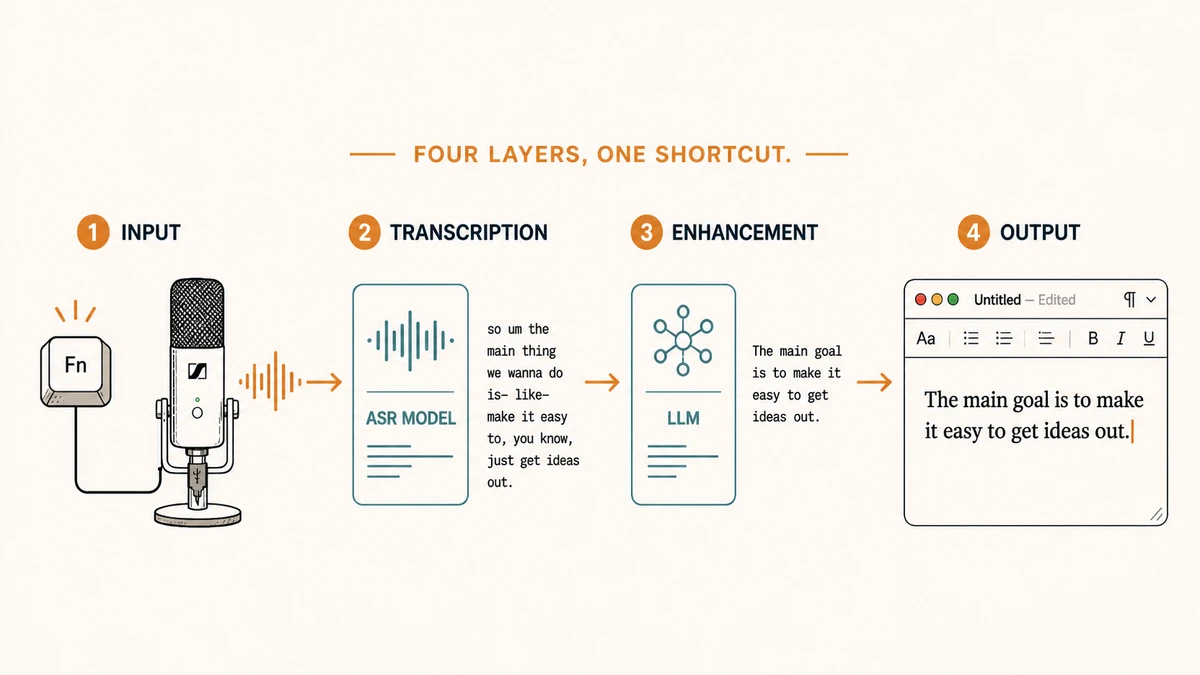
Why now?
time-to-stop-talking + inference time, the two intervals back-to-back. Streaming overlaps them, so by the time I stop speaking most of the work is already done. In practice I'm seeing about 300 ms per turn for a couple of sentences, enough to feel near-instantaneous.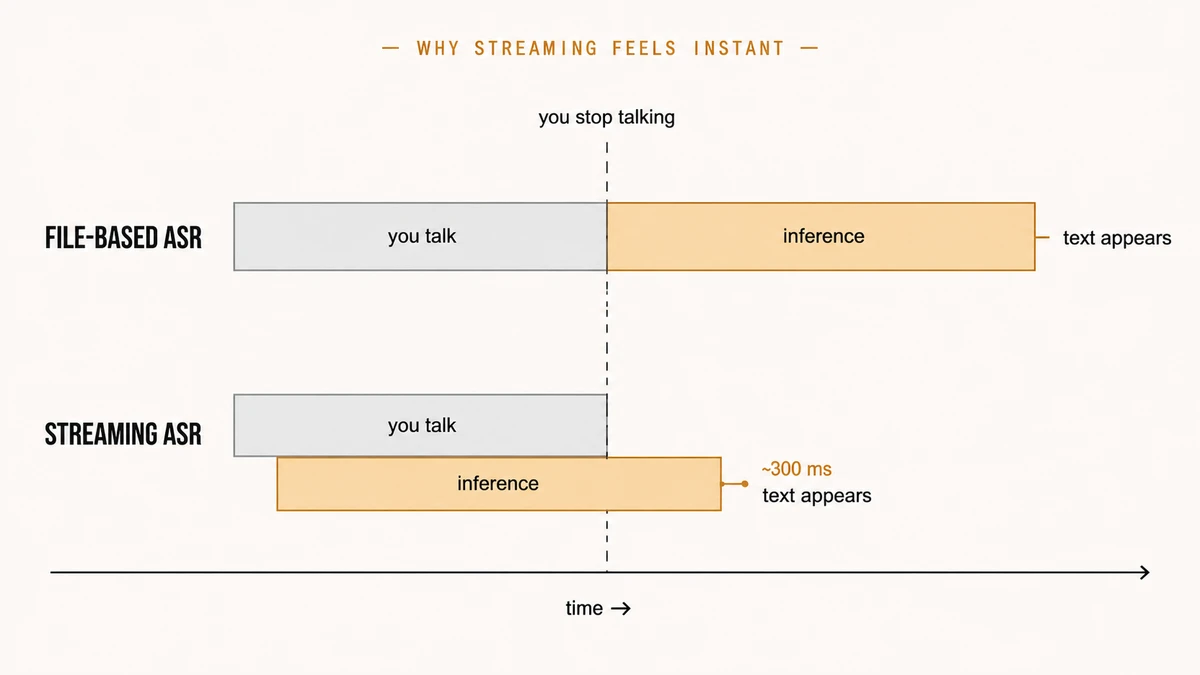
Why VoiceInk?
Beyond dictation
$\sum_{i=0}^n x_i$ where my cursor sits.
This post was written in collaboration with Claude.