Ethereum's Merkle Patricia Trie (Part 1/2)
How Ethereum stores its state, commits it to a single hash, and why that design is hitting its limits Ethereum is the second-largest blockchain by market cap, securing hundreds of billions of dollars in value. Everyone knows it's a distributed ledger. But how does it actually store all that data? Hundreds of millions of accounts. Smart contracts with their own persistent storage: token balances, NFT ownership records, DeFi positions. Over 250 GB of state, replicated across nearly a million validators worldwide, growing every day. The answer is a data structure called the Merkle Patricia Trie. That may soon change. Ethereum's roadmap calls for replacing it to enable stateless validation: verifying blocks without storing the full state. It would be the biggest structural change since genesis. To understand why, we need to understand what's there today, and why it's hitting its limits. Ethereum maintains a world state: a key-value store where each key is an address and each value is an account. There are two account types. Externally owned accounts (EOAs) are controlled by private keys and can initiate transactions. Contract accounts hold code and are triggered by transactions. Both types share the same four data fields: Contracts separate storage from code. Storage (token balances, ownership records, configuration) lives in its own key-value store, nested within the world state via If you were building this at your typical tech company, you'd probably use a flat key-value mapping: address as the key, account data as the value. Lookups are fast, updates are straightforward, and the tooling is mature. Why does Ethereum need anything more complex? Ethereum is a distributed system. Nearly a million validators execute the same transactions and must arrive at identical state. To verify consensus, every node produces a commitment: a short value that represents the entire state. In Ethereum today, this is a 32-byte hash. This commitment goes in the block header. If yours doesn't match, your state has diverged from the network. This creates two key requirements that a flat key-value mapping can't satisfy. To compute a commitment from a flat mapping, you'd need to serialize all entries in some deterministic order and hash them together. Now every time you change one balance, you re-serialize and re-hash the entire state. That's O(n) work per block on 250+ GB of data. A tree fixes this. Each node's hash is computed from its children's hashes. Change a leaf, and only the hashes along the path to the root need updating. That's O(log n) operations instead of O(n). Alice wants to check her balance without trusting anyone. She can't store 250+ GB of state. With a flat key-value store, the only way to verify a value is to recompute the commitment yourself, which requires having the entire state. A tree fixes this too. To prove a value exists, the prover provides the path from that leaf to the root, plus enough information (a proof) at each level to recompute the hashes. Alice (the verifier) can then reconstruct the root hash from this small proof and check it against the known root. We've established that we have a key-value store (addresses → accounts) to organize into a tree. How? By using a trie (pronounced "try," from retrieval). A trie uses the key itself as the path through the tree. Each character in the key determines which branch to take. For a hex key like Ethereum uses a hexary trie: one child per hex digit (0-F), giving a maximum width of 16. The depth depends on key length. Before insertion, each address is hashed with keccak256, producing a 32-byte key (64 hex digits).2 Contract storage keys are hashed the same way. Both tries have a maximum depth of 64. The Patricia variant used by Ethereum compresses the trie by collapsing branch nodes with only one child into an extension node (purple in the figure above). We have the trie structure. Now we are ready to add the Merkle part. In a plain Patricia trie, each node represents a hex digit in the key. In a Merkle trie, each node also has a hash computed from its children's hashes. Change any leaf, and every node on the path to the root gets a new hash. How is each node's hash computed? For a branch node, combine references to all of its children and hash the result with keccak256. The output is a single 32-byte hash. The root hash commits to the entire state, which goes into every block header. Any validator can compute the state root after executing a block's transactions and verify it matches. And because only the path from a changed leaf to the root needs rehashing, we get the O(log n) updates promised earlier—efficient commitment. What property does this rely on? Collision resistance: it's computationally infeasible to find two distinct states that produce the same keccak256 root. The root hash uniquely identifies the state. The actual Ethereum implementation is more complex: RLP encoding to serialize nodes before hashing, different array specs for different node types (branch, leaf, and extension), flags for even/odd path lengths. Trie nodes are stored in a key-value database (historically LevelDB, though clients now vary). Each key is the keccak256 hash of the node's RLP-encoded content; each value is the node itself. The three node types: To look up a key, start from the root hash (in the block header), fetch the root node, follow the appropriate child based on the next hex digit, and repeat. Each level is a random disk read. The Ethereum documentation covers this in detail. We claimed earlier that a tree enables partial proofs: verifying a single value without the full state. Here's how. Alice wants to verify her Ethereum balance from her phone's wallet. The full state is 250+ GB; she can't store it. Her wallet might query a third-party node provider like Infura or Alchemy behind the scenes, but that provider could be compromised, or lying, or hacked. She'd have no way to know. The Merkle structure offers an alternative. Alice (the verifier) stores just block headers (a few KB each). She asks any full node (the prover) for her balance plus a proof. She recomputes the root from the proof. If it matches the state root in the header, the balance is correct, mathematically guaranteed. Consider a trie of depth $d$ and a path $k = (k_0, k_1, \ldots, k_{d-1})$ where each $k_i$ is a hex digit in the account's hashed key. To prove the value at this path, the prover provides: Verification reconstructs the root bottom-up. Hash the leaf, then work up the tree, combining with siblings at each level: $$H_d = \text{hash}(v)$$ $$H_{i-1} = \text{hash}(h_{i,0} | h_{i,1} | \cdots | h_{i,15})$$ $$\text{where } h_{i,j} = \left\lbrace \begin{array}{ll} H_i & \text{if } j = k_{i-1} \\ S_i[j] & \text{otherwise} \end{array} \right.$$ If $H_0$ matches the state root, the proof is valid. The prover must supply the full account (if any field were wrong, the leaf hash would differ and the proof would fail), but the verifier never sees the rest of the state; just the sibling hashes along the path: Suppose hashing Alice's address produces a key starting with What about values in contract storage? Recall that each account has a Alice can verify a single state value with a Merkle proof. Validators do something similar thousands of times per block: read state, execute transactions, compute a new state root. Ethereum's core commitment is decentralization. As Vitalik Buterin put it: "In the longer term there's a plan to maintain fully verified Ethereum nodes where you could literally run it on your phone." Validation should be accessible to ordinary hardware, not just data centers. Currently the world state grows by roughly a gigabyte per week. As it grows, less of the trie fits in memory, so more lookups require random disk reads. As I covered in a previous article, accessing data on disk can create bottlenecks. To meet Ethereum's 12-second slot constraint, validators need faster storage (SSDs at minimum, increasingly NVMe-class), pushing costs upward and working against the decentralization goal. But what if validators didn't store state at all? Instead of reading from disk, they could receive proofs for every value a block touches. The same trick Alice used, scaled up. The problem is proof size. Each proof requires sibling hashes at every level: 15 siblings × 64 levels × 32 bytes ≈ 30 KB worst case, ~3 KB on average. With current blocks using ~30M gas and cold state reads costing 2100 gas each,3 a block easily touches thousands of values. At ~3 KB average, that's several MB of additional bandwidth per block. 10 MB incremental per block would be over 2 TB/month in extra bandwidth per validator: the kind of overhead that pushes solo stakers toward data centers. So proof size is a binding constraint. Shrink the proofs, and stateless validation becomes viable. One approach to shrinking proofs: replace hash-based commitments with polynomial commitments. Verkle trees do exactly this, reducing proofs from several KB to less than 150 bytes each. Ethereum's state tree is actually now headed a different way (a binary trie with post-quantum hash-based commitments), but the underlying cryptography is very relevant: polynomial commitments are the foundation of zero-knowledge proofs, a rapidly advancing field with applications across Ethereum's scaling roadmap and well beyond. Part 2 covers how Verkle trees work, building on finite fields and elliptic curves. State growth adds another problem: stateless validation may let validators skip storing state, but the full state must still exist somewhere to construct blocks. New storage primitives like expiring storage and UTXO-style records are currently being discussed and could keep that 250+ GB from growing indefinitely. You could by reducing tree width, but in the current architecture the tradeoffs are steep. Each level of trie traversal is a random disk read: the root node points to a child at one location, which points to another child elsewhere. A hexary trie with effective depth ~8-10 means 8-10 random reads per lookup. A binary trie would have depth ~30-40. Even on NVMe, random reads cost tens of microseconds each. Multiply by thousands of state accesses per block, and going binary would blow through the 12-second slot time. Hexary branching was a natural fit for hex-encoded keys, while keeping the trie shallow enough for fast lookups. And the payoff isn't even that good. A binary trie needs only 1 sibling hash per level instead of 15, but it's 4× deeper (since $\log_2 n = 4 \log_{16} n$). Net effect: 15× fewer siblings per level, 4× more levels, so proofs shrink by roughly 15/4 ≈ 4×. If hexary proofs run ~10 MB per block, binary gets you to ~2.5 MB... still a significant network overhead. Under stateless validation, where validators verify proofs rather than traverse the trie, depth stops being a bottleneck, but the proof-size overhead remains. Other tokens like USDC are tracked in contract storage. ↩ keccak256 is Ethereum's hash function; the pre-standardization version of what became SHA-3. Hashing prevents attackers from crafting addresses that create pathologically unbalanced branches. ↩ EIP-2929 distinguishes cold reads (first access, 2100 gas) from warm reads (subsequent, 100 gas). Using cold cost here underestimates total accesses. ↩
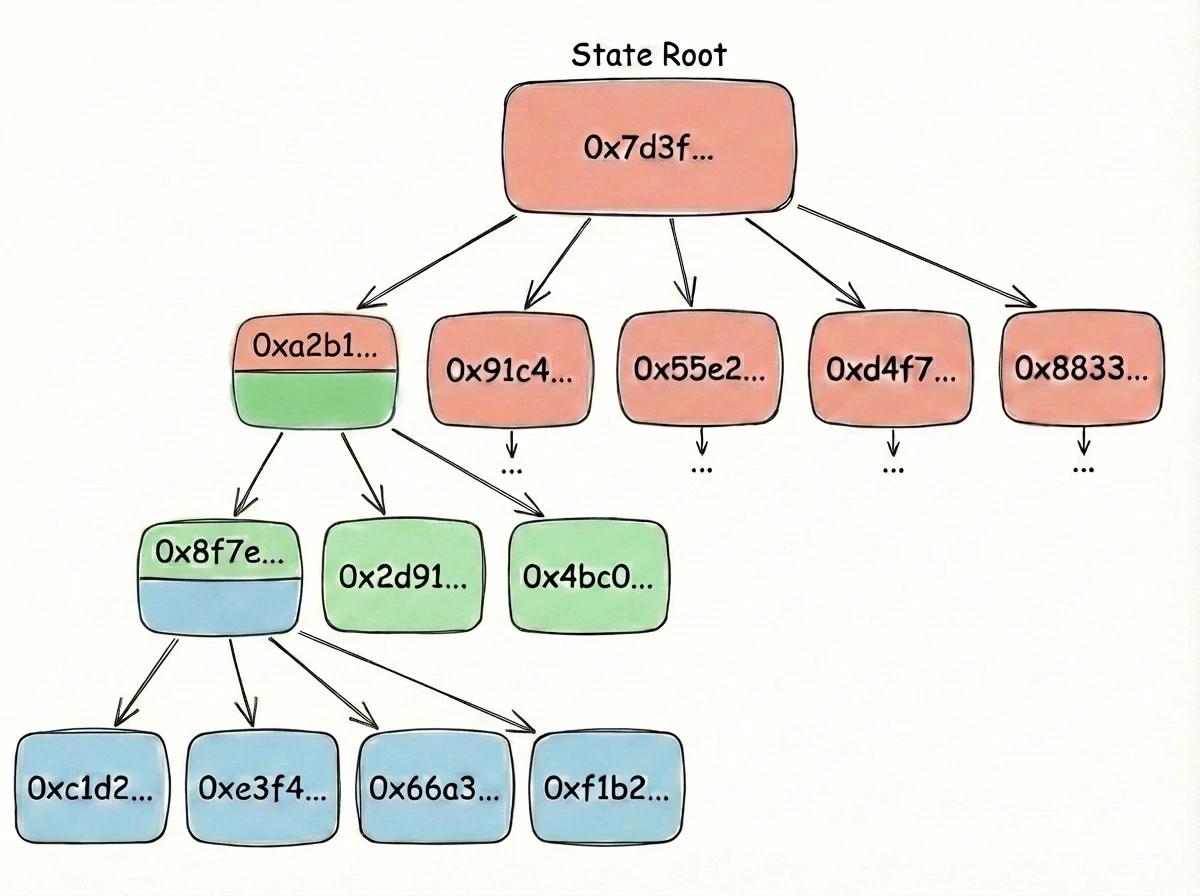
The World State
storageRoot. Code is stored on-chain but outside the world state, referenced by codeHash. We'll revisit this nested storage when we discuss Merkle proofs.Why a Tree?
1. Efficient commitment
2. Partial proofs
Tries: Keys as Paths
4a7f..., you start at the root, branch on 4, then a, then 7, then f, and so on until you reach the stored value. You don't store keys explicitly; the path is the key.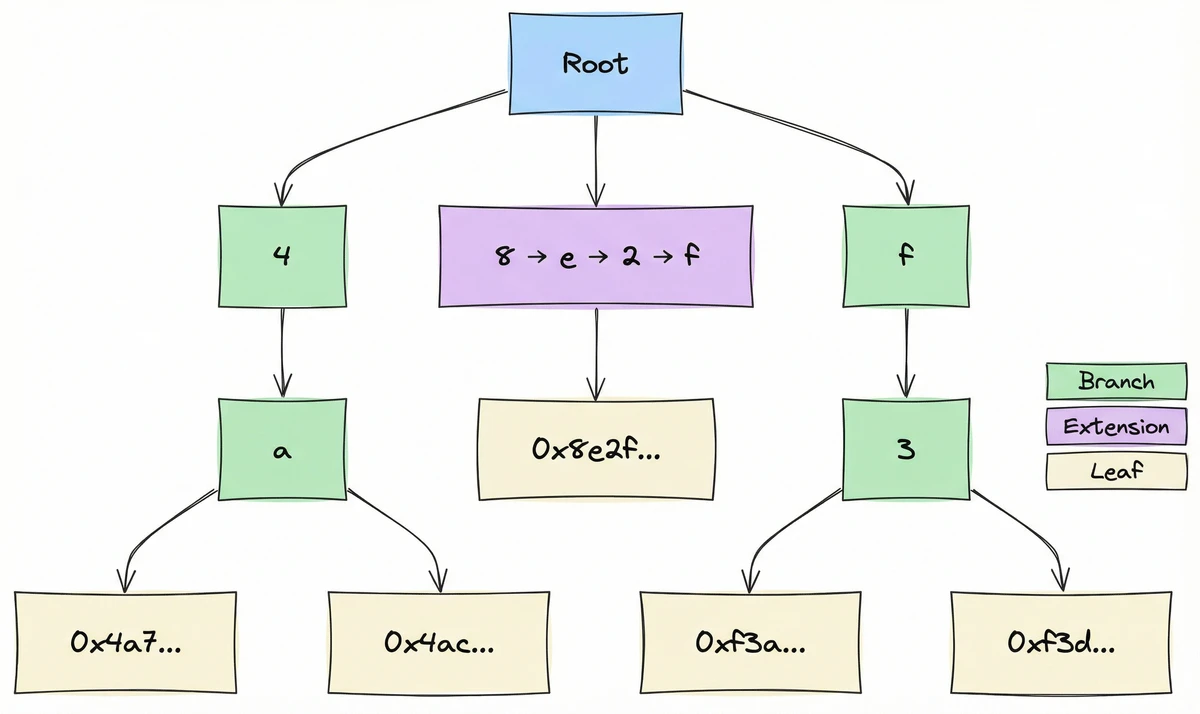
Merkle Patricia Tries
More on the implementation
[v0, v1, ..., v15, vt]. Each vi points to a child for hex digit i (or empty). vt holds a value if a key terminates here.[encodedPath, value]. The path encodes remaining key nibbles; the value is the account data.[encodedPath, nextNode]. Compresses chains of single-child branches into one node (the Patricia optimization).Merkle Proofs
Proof and Verification
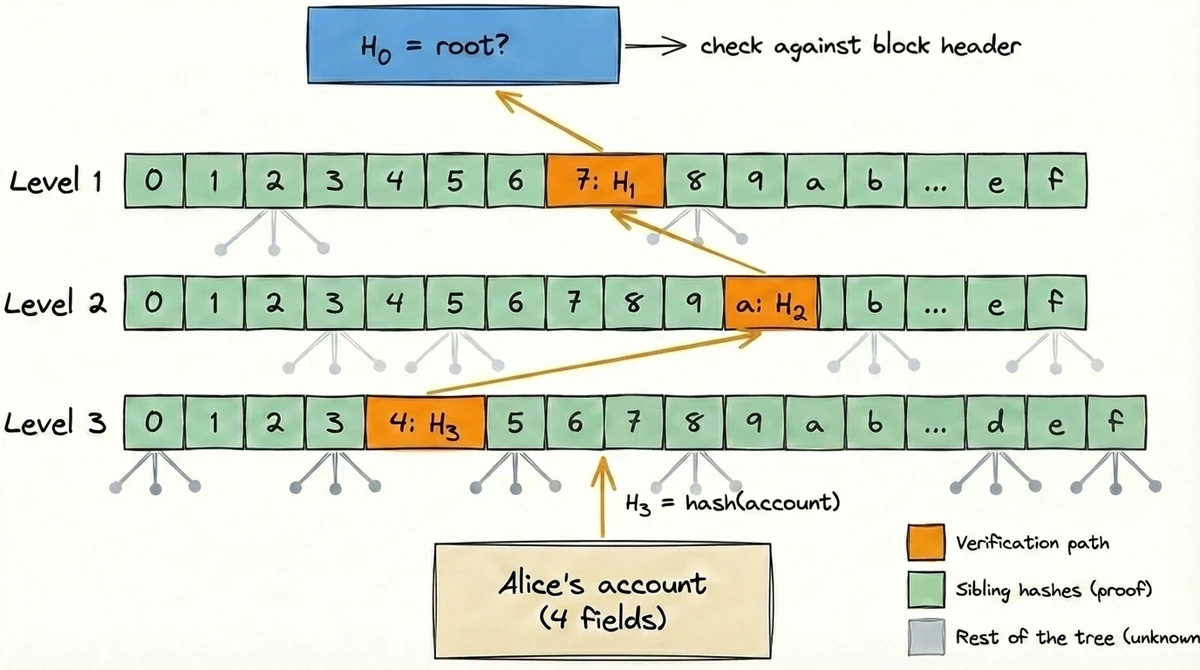
Walkthrough
7a4.... In a simplified 3-level trie, the path is $k = (7, a, 4)$. The proof contains Alice's account data plus up to 45 sibling hashes (15 at each of the 3 levels). Verification proceeds bottom-up:4 among its siblings, hash all 16 → $H_2$a among its siblings, hash all 16 → $H_1$7 among its siblings, hash all 16 → $H_0$storageRoot, the root of another trie containing that contract's storage. To prove a storage value, you provide two proofs: one from the state root to the account (which includes storageRoot), and another from storageRoot to the storage slot. The same verification logic applies, just nested.Smaller Proofs, Bigger Possibilities
What's Next
Appendix
Could we shrink Merkle proofs by reshaping the tree?
This post was written in collaboration with Claude.