When Parquet Files Beat CSV
The physical reality that makes file layout matter Back in December 2021, I was leading a new team at Amazon building a trend analytics application. We had data flowing into S3 as CSV files, getting ingested into a database, feeding weekly batch jobs. A data engineer proposed switching the storage format from CSV to Parquet. A debate ensued. Parquet won. I'll be honest: I never deeply understood why. When I pressed for reasons, I heard that columnar storage was better for performance, offered better compression, and so on. It felt a bit too good to be true. I didn't have a firm grasp of the trade-offs, let alone the mechanics behind the benefits. It was my first 90 days into the role, so I did what many managers do: went with my gut and moved on. This post is my attempt to finally get it. On disk, a file's data is stored as a contiguous sequence of bytes:1 $[b_0, b_1, b_2, \ldots, b_n]$ where each $b_i$ is a byte (8 bits, each 0 or 1) and $n$ typically ranges from millions (MB) to billions (GB) for analytics workloads. Analytics queries rarely need all this data. A typical query might aggregate one column, filter on another, and ignore the rest. If your file has 100 columns and 10 million rows, but your query only touches 3 columns, reading the entire file means transferring 30x more bytes than necessary. At scale—hundreds of files, each gigabytes—this overhead dominates. Reading entire files is not viable. So you need to be surgical: extract only the bytes you actually need. Two operations let you do this: The file layout determines whether the data you need is contiguous (one seek) or scattered (many seeks). But there's a constraint: seek is expensive relative to read. A traditional hard drive has ~10ms access latency (the seek) and 150 MB/s throughput (the read). Compare: Going from 10 bytes to 1MB (100,000x more data) doesn't even double the I/O time if the data being read is contiguous. The goal is clear: minimize seeks, maximize bytes per seek. The strategy that achieves this is called batching: read large contiguous chunks instead of many small reads scattered across the file. The same principle applies to cloud object storage like S3. AWS's disks still have seek overhead, but from your perspective the bottleneck is HTTP request overhead (TCP, TLS, round-trip). Batching here means requesting large byte ranges per HTTP request. Unlike disk (one read head), S3 lets you issue multiple requests in parallel, but concurrency is limited so the goal remains the same: fewer requests with larger byte ranges. Analytics data is typically tabular: rows and columns. When you serialize a table into a byte sequence, there are two natural choices. Consider a simple employee table: Row-oriented (CSV): store each row contiguously, then the next row. Column-oriented (Parquet): store each column contiguously, then the next column. This changes which bytes you need to read. Consider With CSV, columns are interleaved within each row. You could read the entire file and discard what you don't need, but we just established that's not viable at scale. What if you had an index telling you exactly where each field starts? Could you then seek directly to name and salary and read just those? You could, but it wouldn't help. To read 2 columns from 1 million rows, you'd need 2 million separate seeks (one per field). At 10ms per seek on HDD, that's 5+ hours of seek time alone. The problem isn't knowing where the data is. The problem is that the data you need is scattered. Row-oriented layout forces you to either read everything or make millions of tiny reads. Neither is acceptable. Columnar layout solves this. Each column is stored contiguously, so reading name and salary means two seeks and two sequential reads. The data you need is physically together. You just need some way to locate where each column starts. That's what Parquet provides. A Parquet file has three key components: As a byte sequence: Row groups (~128MB each) are horizontal partitions of rows. They enable parallel processing: distributed query engines like Spark or BigQuery can assign different row groups to different workers. Column chunks live within each row group. Each column's data is stored contiguously. This is where columnar storage actually happens. Column chunks are further divided into pages (~1MB each), which is where encoding and compression are applied. We won't go into page-level details here. The footer is stored at the end of the file and contains the metadata you need to read surgically: the offset (where to seek), size (how much to read), and statistics (min/max/nulls) for every column chunk in every row group. Here's what the footer looks like (simplified): To read a Parquet file, you first seek to the end, read the footer, then use it to locate exactly the data you need. This structure enables three key benefits: projection efficiency (read only the columns you need), compression (column chunks contain homogeneous data), and predicate pushdown (skip row groups based on statistics). There are additional benefits—parallelism from row groups and type safety from the schema—but these three account for most of why Parquet wins for analytics. Let's put concrete numbers to this. Consider 1 million employee records with 4 columns totaling ~100MB. The query Using the footer from our earlier example: name is at offset 0 (2.1MB), salary is at offset 2.5MB (0.8MB). Two seeks, 2.9MB transferred. On HDD, that's ~40ms total. You skip 97% of the file. Fewer bytes means even faster I/O. The columns you do read can be made smaller still. Within each column chunk, all values share the same type, and in practice they often follow patterns: repeated categories, sequential timestamps, sorted keys. Parquet exploits these patterns through encoding: column-aware transformations applied at the page level. Dictionary encoding for low-cardinality strings (few unique values). Consider 8 department names repeated across 1M rows. Instead of storing "Engineering" 200k times (~12 bytes each), build a dictionary mapping each unique value to a small integer: Delta encoding for sequential integers. Timestamps often increment by small amounts: Run-length encoding (RLE) for consecutive repeated values. If data is sorted, you get long runs:3 After encoding, generic compression (Snappy, Zstd, or others) is applied to the result for further reduction. Both benefit from columnar layout: grouping values by column exposes patterns that shrink file size. Predicate pushdown lets you skip entire row groups without reading them. A predicate is a condition that filters rows: the Query: If 2 of 10 row groups survive, you've eliminated 80% of I/O before reading any actual data. This works for strings too. Min/max use alphabetical ordering, so if a row group has min="Aaron" and max="Cynthia", a query for For high-cardinality columns like Parquet optimizes for analytical reads: many rows, few columns. The costs show up in two places: Writes are expensive and inflexible. Creating a Parquet file requires buffering an entire row group in memory (~128MB), computing statistics for every column chunk, applying encoding, and compressing. CSV is just concatenating strings. And Parquet files are immutable: you cannot append rows without rewriting the file (the footer would be invalidated). With CSV, Not all reads benefit. Single-row lookups are terrible: even with predicate pushdown, you read entire column chunks (megabytes) to retrieve one row. Row-oriented databases use indexes for O(log n) single-record access. And the more columns you select, the less you gain. If your workload is transactional (lots of single-record reads and writes), Parquet is the wrong choice. The format you choose should match your workload: Many systems use both. Postgres for the live app, Parquet files (or a columnar warehouse like BigQuery) for reporting. They serve different purposes. Parquet won the columnar analytics category so thoroughly that innovation moved to adjacent spaces: Arrow for in-memory processing, lakehouses (Delta Lake, Iceberg, Hudi) for transactions and appends on top of immutable files. The underlying principle is the access latency asymmetry: whether it's disk seeks or HTTP round-trips, the cost of starting a read dominates the cost of continuing it. Organize your data so the bytes you need are contiguous, and you win. A simplification: files can be fragmented across non-contiguous disk blocks, and filesystems add abstraction layers. The mental model still holds for understanding layout trade-offs. ↩ SSDs eliminate mechanical seeks and are more forgiving, but the principle holds: few large sequential reads beat many small reads. ↩ Parquet doesn't sort your data. You must sort before writing. The primary sort key benefits most; secondary keys benefit less, and only if low-cardinality. ↩
Files as Byte Arrays
Storage Access Latency Throughput Implication HDD ~10ms (mechanical seek) 150 MB/s Latency dominates; batching essential SSD2 ~0.1ms (no moving parts) 500–3000 MB/s Smaller penalty per seek; batching still wins S3 ~100ms (HTTP round-trip) 100+ MB/s Large byte ranges per request; parallelize across chunks Row vs Column Orientation
name age salary dept Alice 32 95000 Eng Bob 28 72000 Mkt Carol 45 120000 Eng [Alice,32,95000,Eng][Bob,28,72000,Mkt][Carol,45,120000,Eng][Alice,Bob,Carol][32,28,45][95000,72000,120000][Eng,Mkt,Eng]SELECT name, salary: you need 2 of 4 columns.Parquet File Structure
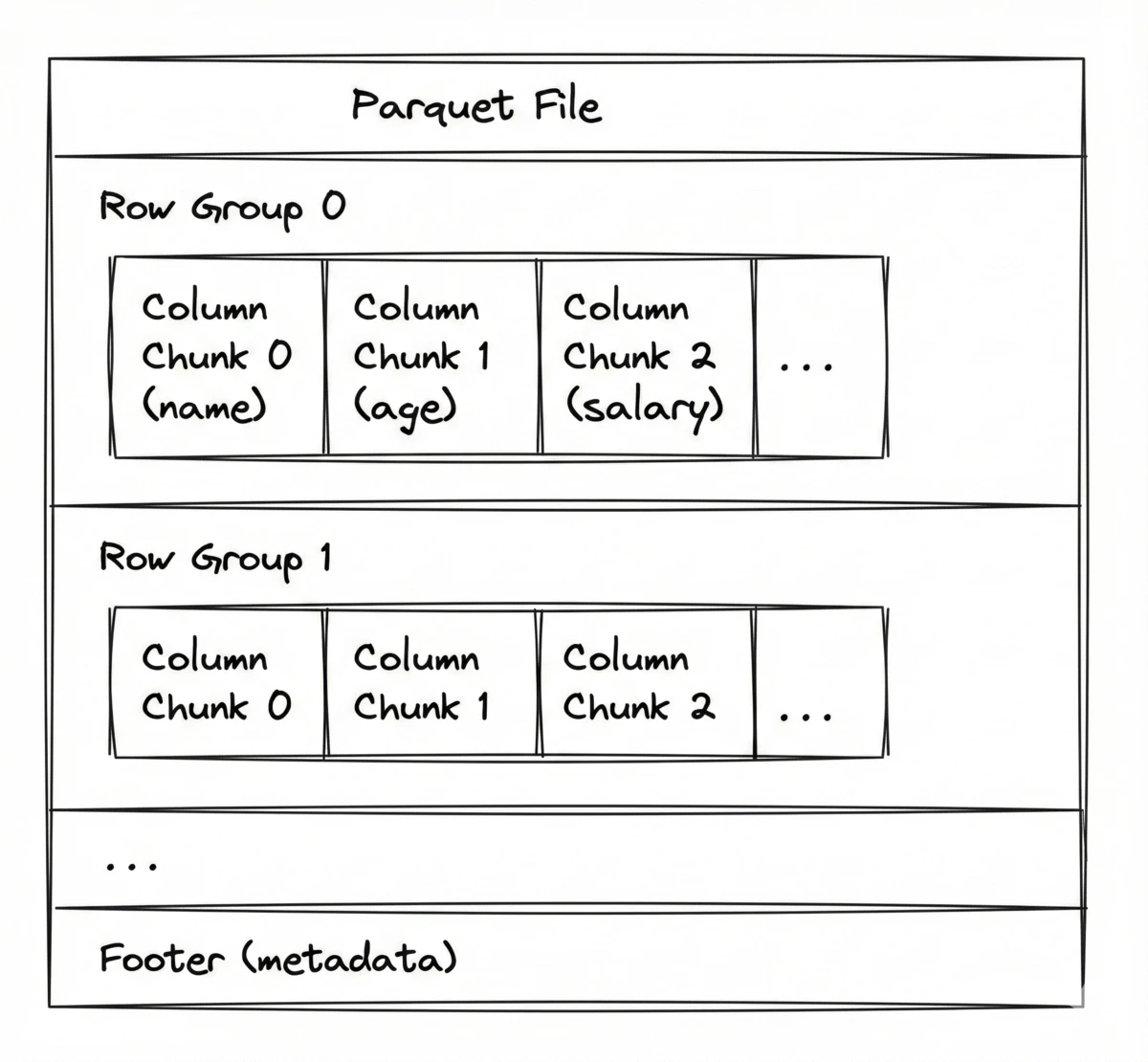
[RG0:Col0][RG0:Col1][RG0:Col2]...[RG1:Col0][RG1:Col1][RG1:Col2]...[Footer]Footer:
Schema: name (STRING), age (INT32), salary (INT64), dept (STRING)
Row Group 0 (rows 0–99,999):
name: offset=0, size=2.1MB, min="Aaron", max="Cynthia", nulls=0
age: offset=2.1MB, size=0.4MB, min=18, max=67, nulls=12
salary: offset=2.5MB, size=0.8MB, min=31000, max=185000, nulls=0
dept: offset=3.3MB, size=0.1MB, min="Design", max="Sales", nulls=0
Row Group 1 (rows 100,000–199,999):
...1. Projection Efficiency
SELECT name, salary needs only 2 columns.2. Compression
{0: "Design", 1: "Engineering", ...}. Then store just the integer codes (1 byte each) instead of the full strings. ~12:1 compression.[1704067200, 1704067201, 1704067203, ...]. Instead of storing each 8-byte value, store the first value once, then just the differences: [1704067200, +1, +2, ...]. Deltas fit in 1–2 bytes. ~4–8:1 compression.Design, Design, ...(50k times)..., Engineering, .... Instead of repeating the value, store it once with a count: (Design, 50000), (Engineering, 200000), .... Compression scales with run length; a 50k run becomes a single (value, count) pair.3. Predicate Pushdown
WHERE clause in SQL. In a query execution plan, operations form a hierarchy—read data at the bottom, transform and filter higher up. "Pushdown" means moving the filter down that hierarchy, from the query engine to the storage layer. Instead of reading data and then discarding rows that don't match, you skip them before reading. The footer's min/max statistics make this possible: Parquet can check whether a row group could possibly contain matches without reading the actual data.SELECT name FROM employees WHERE salary > 200000name = 'Zoe' can skip it entirely.Bloom filters for high-cardinality columns
user_id, min/max is useless (the range spans everything). Bloom filters offer an alternative: a bit array with multiple hash functions that answers "definitely not here" or "maybe here." A false positive ("maybe here" when the value isn't actually there) means a wasted read. The rate follows $(1 - e^{-kn/m})^k$ where $k$ is hash functions, $n$ is rows, $m$ is bits—and there's a closed-form formula for the optimal $k$ that minimizes this rate. A topic for another post.The Tradeoffs
echo "new,row" >> file.csv just works.SELECT * reads everything, losing the projection benefit (though compression still helps), and pays reconstruction overhead to stitch columns back into rows.Takeaway
This post was written in collaboration with Claude.