Verkle Trees: Polynomial Commitments (Part 2/2)
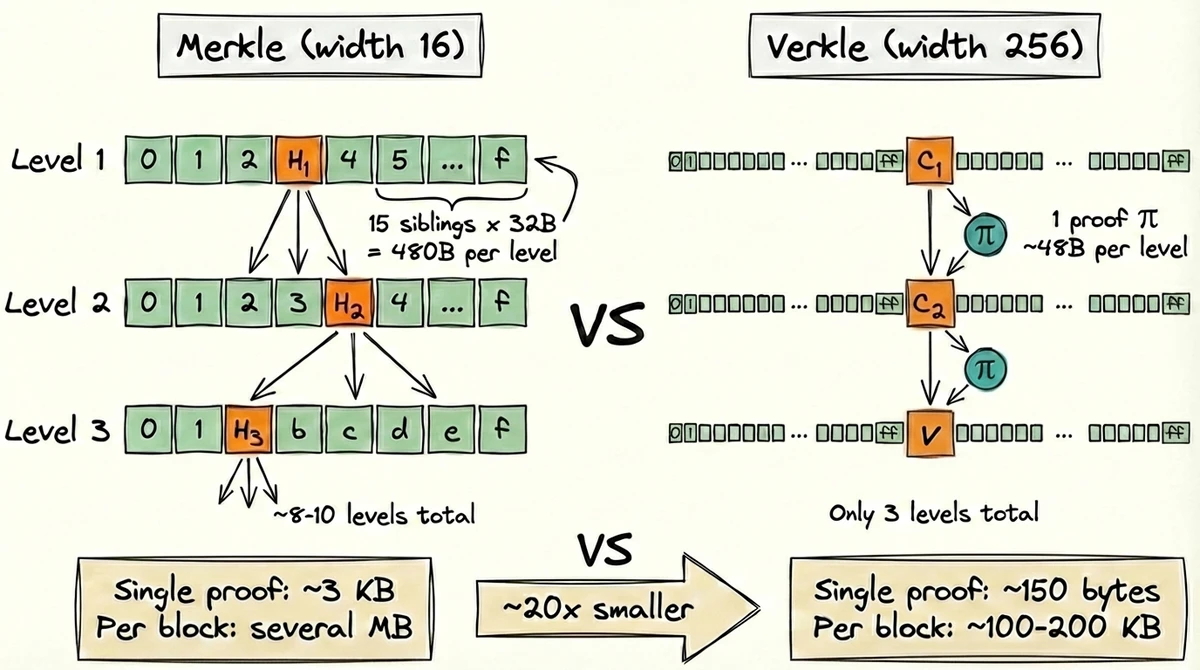
How a single curve point can commit to 256 children, and why proofs shrink from kilobytes to bytes Part 1 ended with a problem: Merkle proofs in Ethereum's state trie are too large for stateless validation. At several MB per block, the bandwidth cost of including proofs would push solo validators toward data centers. Verkle trees offer an answer: replace hash-based commitments with polynomial commitments. Each node stores a curve point instead of a hash, and nodes widen from 16 children to 256. Instead of proving a leaf by providing every sibling hash on the path to the root (~3 KB), the prover sends a small proof at each level (~150 bytes), roughly 20x smaller. By the end of this post, you'll understand how. The central idea is to build a vector commitment: a scheme that commits to many values and lets you prove any single one without revealing the others. This is what puts the "V" in Verkle (Vector commitment + Merkle).1 Same tree structure, different commitment at each node. We do it with polynomials. Represent all 256 children of a node as evaluations of a single polynomial: $$P(x) = a_0 + a_1 x + a_2 x^2 + \cdots + a_{255} x^{255}$$ We pick positions $0, 1, \ldots, 255$ and choose the coefficients $a_0, \ldots, a_{255}$ so that: $$P(i) = v_i \quad \text{for } i = 0, 1, \ldots, 255$$ This gives us a degree-255 polynomial that passes through every child value. Such a polynomial always exists and is unique: any $n$ position-value pairs determine exactly one polynomial of degree $n - 1$.2 The algorithm that finds this polynomial is called Lagrange interpolation. The idea: build basis polynomials that each equal 1 at one point and 0 at all others, then take their weighted sum. For $n$ points, the Lagrange basis polynomial for position $j$ is: $$L_j(x) = \prod_{\substack{m=0 \\ m \neq j}}^{n-1} \frac{x - m}{j - m}$$ $L_j(j) = 1$ and $L_j(m) = 0$ for all $m \neq j$. The full polynomial is their weighted sum: $$P(x) = \sum_{i=0}^{n-1} v_i L_i(x)$$ For example, with 4 points, the basis polynomial for position 0 is: $$L_0(x) = \frac{(x-1)(x-2)(x-3)}{(0-1)(0-2)(0-3)}$$ This equals 1 when $x = 0$ and 0 at $x = 1, 2, 3$. The full polynomial $P(x) = v_0 L_0(x) + v_1 L_1(x) + v_2 L_2(x) + v_3 L_3(x)$ passes through all four values. So far this is just algebra. We have a polynomial that encodes the children, but sharing $P$ directly would mean transmitting all 256 coefficients, no better than sending the children themselves. We need a way to compress $P$ into a short commitment. That's where elliptic curves come in. Heads up: all arithmetic from here on (the polynomial's coefficients, its evaluations, the elliptic curve's scalars) happens over the same finite field $\mathbb{F}_p$. Suppose there's a secret scalar $s$ that nobody knows, but everyone has access to the following public parameters: $$G, \ sG, \ s^2G, \ \ldots, \ s^dG$$ How $s$ is generated and destroyed is covered in the Appendix. For now, take these points as given. To commit to $P(x)$, the prover computes: $$\begin{aligned} C &= a_0 \cdot G + a_1 \cdot sG + \cdots + a_d \cdot s^dG \\ &= P(s) \cdot G \end{aligned}$$ Note that the prover doesn't need $s$ to compute $C$: they just combine their polynomial's coefficients with the public parameters.3 The result is a single curve point (48 bytes compressed) that commits to the entire polynomial. Just as a collision-resistant hash won't produce the same output for two different inputs, this commitment is binding: two different polynomials $P \neq Q$ satisfy $P(s) \neq Q(s)$ with overwhelming probability, so their commitments $C = P(s) \cdot G$ are distinct.4 Each Verkle node now stores this $C$ instead of a hash. We have the commitment; now we need a way to prove what's inside it. Alice wants to open the commitment $C$ at position $z$ to verify it holds value $y$. The prover must convince her that $P(z) = y$ without revealing $P$ or any other child. How? The key insight comes from polynomial algebra: if $P(z) = y$, then $P(x) - y$ has a root at $x = z$, so $(x - z)$ divides it evenly. We define the quotient polynomial: $$Q(x) = \frac{P(x) - y}{x - z}$$ This division is exact if and only if $P(z) = y$. A false claim leaves a remainder, so the prover can't produce a valid $Q$. The opening proof $\pi$ is simply a commitment to $Q$: $$\pi = Q(s) \cdot G$$ One curve point. No siblings needed. Now the verifier needs to check that $Q$ is legitimate. If the division was exact, multiplying back gives a polynomial identity that holds at every point, including $x = s$: $$P(s) - y = Q(s) \cdot (s - z) \tag{1}$$ The verifier can't check this equation directly. They have $C = P(s) \cdot G$ and $\pi = Q(s) \cdot G$, but the curve points hide their scalars: extracting $P(s)$ or $Q(s)$ from them is the discrete logarithm problem. And $(s - z)$ requires knowing $s$, which nobody has. A pairing $e$ is a function that takes a point from one curve group ($\mathbb{G}_1$) and a point from another ($\mathbb{G}_2$) and outputs an element in a target group, with the property of bilinearity: $$e(aG_1, bG_2) = e(G_1, G_2)^{ab}$$ Feed in a point hiding some scalar $a$ and another hiding $b$, and the output captures their product. We can't extract $a$ or $b$, but we can check whether two products are equal by comparing pairing outputs.5 Pairings require two distinct curve groups; the $G$ we've been using lives in $\mathbb{G}_1$ (becoming $G_1$), and $G_2$ is a generator in $\mathbb{G}_2$. The public parameters also include $sG_2$. The strategy: express each side of equation $(1)$ as a product of two scalars, then feed one factor into $\mathbb{G}_1$ and the other into $\mathbb{G}_2$. The right side naturally factors as $Q(s) \cdot (s - z)$. The left side is just $(P(s) - y) \cdot 1$, so we pair it with the plain generator $G_2$: Left side: $(P(s) - y)G_1 = C - yG_1$, so $$e(C - yG_1, G_2) = e(G_1, G_2)^{P(s) - y}$$ Right side: $Q(s) \cdot G_1 = \pi$ and $(s - z)G_2 = sG_2 - zG_2$, so $$e(\pi, sG_2 - zG_2) = e(G_1, G_2)^{Q(s)(s-z)} $$ These are equal if and only if equation $(1)$ holds, so verification reduces to a single check: $$e(C - yG_1, G_2) = e(\pi, sG_2 - zG_2) \tag{2}$$ The verifier knows every variable in this equation: $C$ and $\pi$ came from the prover, $y$ and $z$ are the claimed value and position, and $G_1$, $G_2$, $sG_2$ are public parameters. One pairing check, no siblings. Step back and consider what we just built. A node with 256 children gets encoded as a polynomial and mapped to a single curve point. To open one child, the prover divides out the corresponding root, producing a quotient polynomial, and maps it to a second curve point. A pairing function then reaches across two curve groups and, through bilinearity, verifies the division was exact from the curve points alone. Two points, one check, done. That this works at all feels like reaching through a crack in the universe. This commit-open-verify scheme is called KZG (Kate-Zaverucha-Goldberg): produce one commitment per node, one opening proof per level. A Merkle tree with width 16 needs ~8-10 levels and 15 sibling hashes (480 bytes) at each one. A Verkle tree with width 256 covers the same state in just ~3 levels,6 with a single ~48-byte proof at each: Alice wants to verify her ETH balance. Her hashed address gives the positions $k_0, k_1, k_2$ that trace a path: root $\to$ $C_1$ $\to$ $C_2$ $\to$ leaf $v$. The prover sends Alice the leaf value $v$, the intermediate commitments $C_1$ and $C_2$, and an opening proof $\pi_i$ at each level. Alice verifies bottom-up: That's three opening proofs (~48 bytes each), about 150 bytes total. Polynomial commitments also remove a tradeoff that hash-based Merkle proofs face. In a Merkle tree, narrower means smaller proofs (fewer siblings per level), but deeper means more disk reads per lookup (the bottleneck from Part 1's appendix). Stateless validation eases the depth side, but proof size still grows with width. With polynomial commitments, it doesn't: nodes can be wide and the tree shallow. The figures above reflect KZG proof sizes. Ethereum's Verkle tree proposal swapped in different building blocks: a different commitment type (Pedersen), proof technique (IPA), and curve (Bandersnatch). The architecture is the same; individual proofs are larger (~544 bytes) and verification slower, but the tradeoff worth it: no trusted setup. If the secret $s$ in a KZG ceremony were ever reconstructed, the entire scheme would break. For a state tree securing all of Ethereum's value, the community preferred eliminating that risk entirely. At block level, Dankrad Feist's multiproof scheme merges all opening proofs across a block into a single constant-size proof (~200 bytes), regardless of how many state accesses the block contains. Verkle trees now look unlikely to make it into Ethereum: their reliance on elliptic curve cryptography isn't quantum-resistant, and the community is leaning toward a hash-based binary state tree instead. The ideas we built here (committing to data with polynomials, proving properties without revealing everything), though, are foundational to something bigger: zero-knowledge proofs. They provide a way to prove not only state access, but that an entire block's execution was correct in a single, compact proof. Smaller proofs don't solve every problem (e.g., someone still has to store the ever-growing state to construct blocks), but increasingly, the goal is to prove more and store less. The cryptography behind zero-knowledge proofs, from arithmetic circuits to the difference between proof systems, is something I'll explore on this blog soon. Stay tuned. KZG commitments require public parameters: the curve points $G, sG, s^2G, \ldots, s^dG$. The secret $s$ must be destroyed after generation. How do you destroy a number that nobody should ever know? The ceremony uses multi-party computation. Participants contribute randomness sequentially: The final output is $(s_1 s_2 \cdots s_n)^i G$. The combined secret $s = s_1 s_2 \cdots s_n$ is secure as long as at least one participant honestly destroyed their contribution. Even if every other participant is malicious, one honest party is enough. Ethereum ran exactly this kind of ceremony for EIP-4844 (proto-danksharding) in early 2023. Over 140,000 participants contributed, making it the largest trusted setup ceremony ever. The resulting parameters are used for blob commitments on Ethereum today. The name and construction were introduced by John Kuszmaul in Verkle Trees (2018). ↩ Existence: Lagrange interpolation constructs $P$ directly. Uniqueness: suppose $P$ and $Q$ both pass through the same $n$ points. Then $D = P - Q$ is zero at all $n$ points, but $D$ has degree at most $n-1$, so at most $n-1$ roots. Contradiction unless $D = 0$, i.e., $P = Q$. See Polynomial interpolation (Unisolvence Theorem). ↩ This works because scalar multiplication distributes over point addition: $a_0 \cdot G + a_1 \cdot sG = (a_0 + a_1 s)G$. The map $f(a) = aG$ is a group homomorphism from scalars to curve points. ↩ If $P \neq Q$, then $D = P - Q$ is a non-zero polynomial of degree at most $d$, so it has at most $d$ roots in $\mathbb{F}_p$. For the commitments to collide, $s$ would have to be one of those $\leq d$ values out of $p$ total. That probability is at most $d/p$, which is negligible since $p \sim 2^{255}$ and $d = 255$. ↩ Pairing-friendly curves have special structure that enables this. Not all elliptic curves support pairings. BLS12-381, used in Ethereum today, was designed specifically for efficient pairings. ↩ With 256 children per node, $256^3 \approx 16.7$ million and $256^4 \approx 4.3$ billion. Ethereum has roughly 250 million accounts plus contract storage slots, so depth 3-4 covers the current state. ↩ Polynomial evaluations must be scalars, but $C_2$ and $C_1$ are curve points. Branch nodes handle this by mapping each child commitment to a field element (e.g., its serialized x-coordinate) before interpolating the polynomial. The same applies to step 3. ↩
From Values to a Polynomial
How Lagrange interpolation works
One Curve Point for an Entire Polynomial
Opening Proofs: Proving a Single Value
Verifying the Proof with Pairings
Putting It All Together
Walkthrough
Ethereum's Verkle Proposal: IPA
What's Next
Appendix
The Trusted Setup Ceremony
This post was written in collaboration with Claude.