Rien que la dictée
Comment une app Mac indé à 25 $ a remplacé mon clavier. Sans abonnement, sans OS vocal. J'ai commencé à expérimenter la dictée sur macOS l'été dernier. La dictée native d'Apple m'agaçait depuis un moment, et la version intégrée à ChatGPT montrait assez clairement que la technologie sous-jacente avait largement dépassé ce que proposait Apple. J'avais fait quelques benchmarks de reconnaissance automatique de la parole (Automatic Speech Recognition, ASR) chez Amazon il y a quelques années, et cela cadrait avec ce que j'observais : l'état de l'art avançait vite, et la dictée native des OS ne suivait pas. J'ai donc fait le tour. Comme la plupart des gens, j'ai évalué Wispr Flow et les autres apps de dictée populaires sur Mac avant de m'arrêter sur VoiceInk. Pendant la majeure partie de l'année, je l'ai utilisée de façon sporadique et j'en étais assez content. Il y a environ un mois, ça a changé, et mon usage a fortement augmenté. À tel point qu'aujourd'hui je suis officiellement, totalement converti à la voix. Et je suis content d'avoir choisi VoiceInk quand je l'ai fait. Cet article détaille ma configuration actuelle et les choix derrière chaque décision. Et ma conviction sur le tableau plus large : nous sommes à un point d'inflexion où le clavier est en passe de disparaître comme moyen par défaut de parler à nos ordinateurs. Après quarante ans de frappe, c'est l'un des changements les plus marquants que j'ai vus se produire dans l'informatique personnelle. En une phrase : j'appuie sur le raccourci clavier, l'audio passe de mon micro à VoiceInk, qui le transmet à À partir du moment où j'arrête de parler, le texte nettoyé apparaît à l'écran en une à deux secondes, et cette latence reste à peu près constante que j'aie dicté une phrase ou un paragraphe entier (j'y reviens dans la section suivante). La précision est suffisante pour ne corriger qu'un mot ou deux toutes les dix phrases après la passe Gemini. Cette combinaison a inversé mon ratio clavier/voix. Avant, j'écrivais environ 90 % au clavier et 10 % à la dictée ; aujourd'hui c'est essentiellement l'inverse. L'anglais conversationnel tourne autour de 150 à 170 mots par minute, alors que la frappe moyenne sur un clavier de bureau est plus proche de 52 mots par minute. Environ 3× la bande passante, assez pour que revenir au clavier pour de la prose générale donne l'impression de s'obstiner à communiquer en morse. Et la vitesse n'est que la moitié de l'attrait. La friction de la frappe a un coût cognitif discret pour les petites choses (une réponse Slack rapide, une pensée à moitié formée, une question de deux phrases), et la dictée le ramène à zéro. Une partie de ce que j'écris désormais serait restée dans ma tête. Trois choses se sont nettement améliorées pour moi ces dernières semaines. Commençons par la transcription. L'été dernier, j'utilisais un Whisper quantifié en local via Ollama ; bien pour la confidentialité, mais la précision n'était pas suffisante. Je suis donc passé à l'inférence Groq avec le même modèle non quantifié. Ça a bien marché un temps, jusqu'à ce que la latence de Groq remonte au point où j'utilisais de moins en moins le raccourci de dictée. J'ai alors essayé une poignée de services et je me suis arrêté sur Scribe v2 Realtime d'ElevenLabs, sorti à la fin de l'année dernière. Le vrai bond avec Scribe v2 Realtime n'a pas tellement été la précision (elle est légèrement meilleure) que l'architecture en streaming, que j'utilisais pour la première fois. Il transcrit l'audio pendant que je parle encore, au lieu d'attendre la fermeture du fichier pour commencer. Avec l'ASR par fichier, la latence de bout en bout vaut Le deuxième volet est l'enhancement : une seconde passe que VoiceInk applique à la transcription brute pour nettoyer les disfluences, lisser la formulation et appliquer un prompt personnalisé (j'y reviens aussi). Le modèle qui s'est imposé pour moi ici a été Gemini 3.1 Flash-Lite, le palier le moins cher et le plus rapide de la gamme actuelle de Google. Assez intelligent pour suivre un prompt comportant plusieurs clauses, il ajoute environ 1 à 1,5 seconde en moyenne, ce qui trouve le bon équilibre pour moi sur la courbe précision/latence. La mise à niveau du micro est le troisième volet. Les modèles modernes de speech-to-text sont conçus pour résister à un audio dégradé (pensez aux cas d'usage de téléphonie), mais la chute de précision n'est jamais vraiment nulle. Si vous pouvez vous permettre de débourser ~100 $ pour nettoyer votre entrée, faites-le (et vos invités Zoom vous remercieront). Il y a quelques semaines, je suis passé du micro intégré à mon vieux casque Sony XM3 à un Sennheiser Profile USB à condensateur cardioïde, et la qualité du son s'est nettement améliorée. Pour autant que je sache, VoiceInk est une app macOS développée par une seule personne, Prakash Joshi Pax. L'auteur ne fait pas beaucoup de marketing, et je suis tombé dessus de la manière habituelle, en cherchant et en demandant à Claude. Le code source est sur GitHub sous GPL v3, donc vous pouvez le cloner et le compiler vous-même gratuitement. La licence payante coûte 25 $ pour un Mac (ou 49 $ pour le palier multi-Mac) et va directement au développeur. L'app publie une mise à jour toutes les deux semaines environ et offre déjà tout ce dont j'ai besoin (dictionnaires personnalisés, mots déclencheurs qui redirigent vers différents prompts personnalisés, détection d'activité vocale, pour n'en citer que quelques-unes). Elle est aussi BYOK : vous apportez vos propres clés API pour les modèles que vous utilisez. J'utilise la version payante parce que je veux les mises à jour, oui, mais aussi parce que ça me gênerait de ne pas soutenir le travail. Le modèle tarifaire est ce qui m'a convaincu au départ. Paiement unique, pas d'abonnement. J'avais adhéré à la philosophie Once de DHH il y a quelques années, et je ne vois pas comment un abonnement se défend dans ce domaine. Les modèles sous-jacents continuent de s'améliorer et de devenir moins chers chaque trimestre ; facturer des frais récurrents pour la couche d'interface tout en retirant à l'utilisateur le choix des modèles qui tournent ne tient pas la route. Le BYOK peut sembler être un surcoût et une friction supplémentaire, mais en pratique ce n'est ni l'un ni l'autre. Ma facture Gemini revient à moins de 10 cents par mois, et ElevenLabs me coûte environ 3 $ par mois à un volume d'usage quotidien. Le vrai gain de tenir les clés, cependant, c'est la liberté de changer. J'ai déjà changé trois fois le fournisseur de transcription de VoiceInk cette année (Whisper local, puis Groq, maintenant ElevenLabs), sans jamais attendre que l'app rattrape ce qui venait juste de sortir. L'autre chose que vous obtenez avec VoiceInk, c'est un développeur qu'on peut joindre. Quand la fonctionnalité « pause des médias pendant l'enregistrement » de VoiceInk (qui met Spotify et compagnie en pause pendant que vous parlez et reprend après) déconnait chez moi, j'ai ouvert un ticket sur Github et ça a été corrigé rapidement. Quand le Whisper temps réel d'OpenAI est sorti la semaine dernière et que VoiceInk ne le prenait pas encore en charge, j'ai ouvert un autre ticket sur le dépôt et je m'attends à ce qu'il soit résolu d'un jour à l'autre. Ce genre de réactivité est plus difficile à obtenir une fois qu'un produit sert des millions d'utilisateurs et appartient à une grande équipe avec une feuille de route pluriannuelle et un conseil d'administration (cela dit, un projet à une seule personne a ses propres goulots d'étranglement, bien entendu). Wispr Flow a levé 81 M$ pour construire un « système d'exploitation vocal », ce qui est un pari différent sur un autre horizon. Pour ce qu'est la dictée aujourd'hui, en revanche, je ne vois honnêtement pas ce qu'un abonnement à 10 ou 15 $ par mois m'apporte par rapport à 25 $ une seule fois plus quelques dollars d'API par mois. Cela dit, à ce stade, qualifier VoiceInk de logiciel de dictée, c'est déjà employer un mot trop étroit. Prenez les mots déclencheurs. J'en ai un associé à « assistant » : quand une dictée commence par ce mot, VoiceInk redirige la transcription vers un autre prompt qui dit à Gemini de répondre à la question plutôt que de la transcrire. Donc « assistant, what is the time difference between London and Tokyo? » colle la réponse là où mon curseur se trouve, sans fenêtre de chat ni aller-retour de copier-coller. Le raccourci de dictée fait aussi office de raccourci LLM ponctuel. Ou le prompt personnalisé qui traite la plupart de mes énoncés. Une ligne : « Si ma dictée se termine par 'Fix my rambling,' considère tout ce qui précède comme un brouillon et renvoie une version épurée de ce que je voulais dire. » Quand la sortie n'est pas assez serrée, j'ajoute « fix my rambling » et le modèle réécrit sa première passe en quelque chose de plus proche de ce que j'aurais tapé en y mettant le temps. Une autre ligne, ajoutée la semaine dernière : « Si ma dictée se termine par 'in LaTeX,' écris les maths en LaTeX entourées de $. » Donc « somme de i égal zéro à n de x indice i, in LaTeX » colle Ou la capture multilingue. Le modèle de transcription détecte tout seul si je parle anglais, français ou japonais. Mon clavier ne peut imprimer qu'une seule disposition et les deux autres sont ancrées dans la mémoire musculaire, alors que la dictée court-circuite complètement la disposition. Tout n'est pas encore au point. Un point dur que je rencontre régulièrement est la longue traîne de noms et d'acronymes propres à mon univers. VoiceInk a un dictionnaire personnalisé, mais je dois le remplir mot par mot, alors que ce que je voudrais, c'est que l'app signale les mots qu'elle n'a probablement pas compris et me laisse les confirmer par lots plus tard. Et puis il y a la latence. Une à deux secondes, c'est très bien, ne vous méprenez pas, mais ce n'est pas encore assez rapide pour que je ne remarque plus l'attente. Je m'attends à ce que les écarts restants de latence et de précision se referment vite, et à ce que la dictée se fonde dans une catégorie plus large dont le nom est encore à inventer (Voice AI, Voice computing ?). Toute la pile est sur une courbe qui s'accentue. Deux démos des dernières semaines donnent un aperçu de la suite : le 
Ma configuration
ElevenLabs Scribe v2 Realtime pour la transcription, puis envoie le résultat à Gemini 3.1 Flash-Lite avec un court prompt personnalisé, et colle le texte nettoyé dans l'app au premier plan. Quatre couches, un raccourci.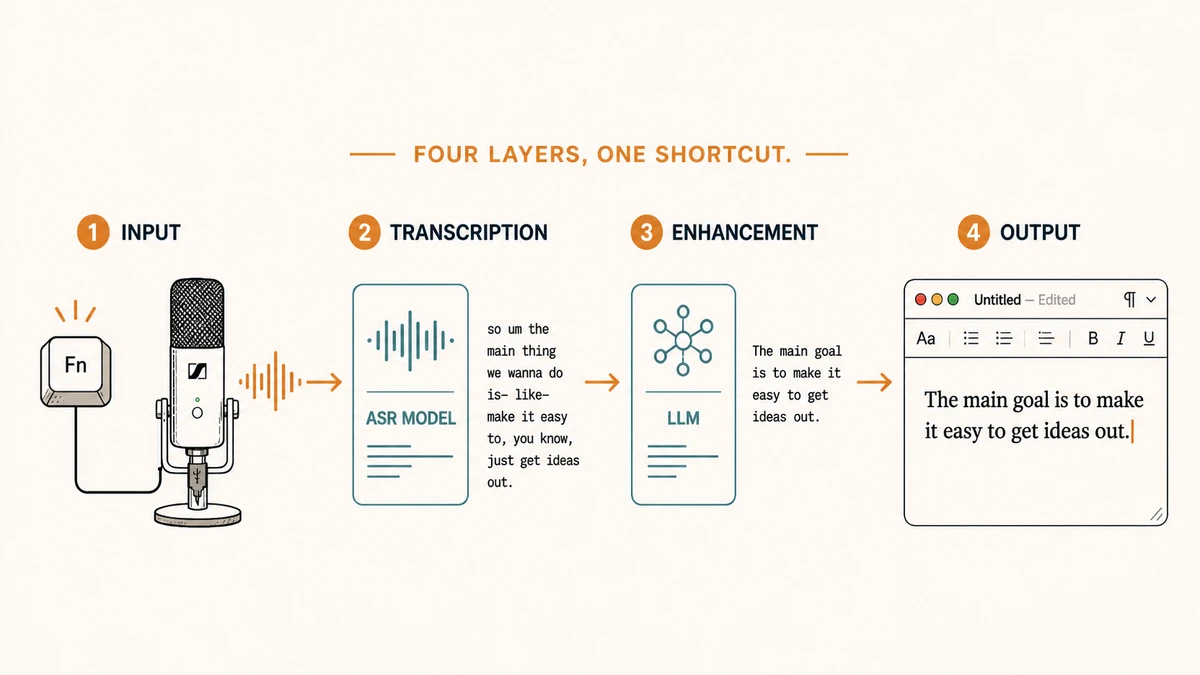
Pourquoi maintenant ?
temps-pour-arrêter-de-parler + temps-d'inférence, les deux intervalles bout à bout. Le streaming les superpose, donc au moment où j'arrête de parler la plus grande partie du travail est déjà faite. En pratique je vois environ 300 ms par tour pour quelques phrases, assez pour donner une sensation de quasi-instantanéité.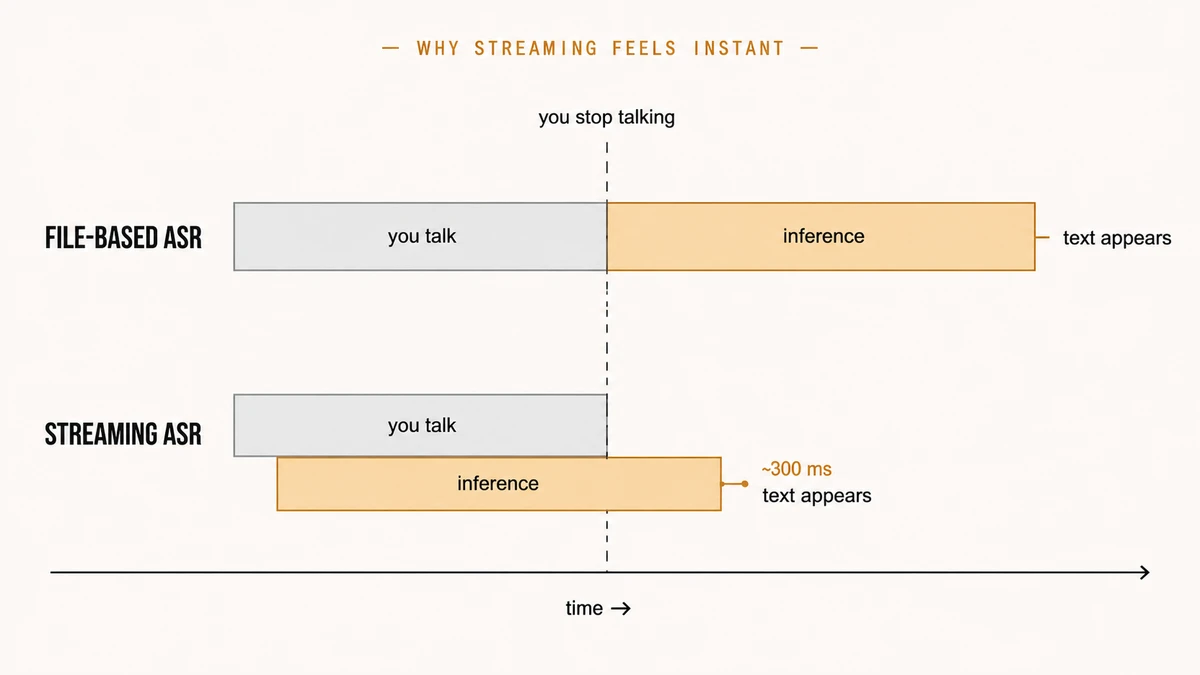
Pourquoi VoiceInk ?
Au-delà de la dictée
$\sum_{i=0}^n x_i$ là où mon curseur se trouve.
gpt-realtime-1.5 d'OpenAI contrôlant l'UI d'une application par la voix, et le pointeur propulsé par Gemini de Google DeepMind, piloté par le mouvement et la parole. Comme pour tout ce qui touche à l'IA en ce moment, il est utile de se rappeler que ce qu'on utilise aujourd'hui est la pire version qu'on utilisera jamais. Et c'est déjà vraiment bon.
Cet article a été écrit en collaboration avec Claude.