Le Merkle Patricia Trie d'Ethereum (Partie 1/2)
Comment Ethereum stocke son état, le condense en un seul hash, et pourquoi cette architecture atteint ses limites Ethereum est la deuxième blockchain par capitalisation boursière, sécurisant des centaines de milliards de dollars de valeur. Tout le monde sait que c'est un registre distribué. Mais comment stocke-t-elle réellement toutes ces données ? Des centaines de millions de comptes. Des smart contracts avec leur propre stockage persistant : soldes de tokens, registres de propriété de NFTs, positions DeFi. Plus de 250 Go d'état, répliqués sur près d'un million de validateurs dans le monde entier, et en croissance chaque jour. La réponse est une structure de données appelée le Merkle Patricia Trie. Cela pourrait bientôt changer. La feuille de route d'Ethereum prévoit de le remplacer pour permettre la validation sans état : vérifier les blocs sans stocker l'état complet. Ce serait le plus grand changement structurel depuis la genèse du réseau. Pour comprendre pourquoi, il faut d'abord voir ce qui existe aujourd'hui, et pourquoi cela atteint ses limites. Ethereum maintient un world state : un store clé-valeur où chaque clé est une adresse et chaque valeur est un compte. Il existe deux types de comptes. Les externally owned accounts (EOAs) sont contrôlés par des clés privées et peuvent initier des transactions. Les contract accounts contiennent du code et sont déclenchés par des transactions. Les deux types partagent les mêmes quatre champs de données : Les contrats séparent le stockage du code. Le stockage (soldes de tokens, registres de propriété, configuration) réside dans son propre store clé-valeur, imbriqué dans le world state via Si on construisait cela dans une entreprise tech classique, on utiliserait probablement un mapping clé-valeur plat : l'adresse comme clé, les données du compte comme valeur. Les recherches sont rapides, les mises à jour directes, et l'outillage est mature. Pourquoi Ethereum a-t-il besoin de quelque chose de plus complexe ? Ethereum est un système distribué. Près d'un million de validateurs exécutent les mêmes transactions et doivent arriver à un état identique. Pour vérifier le consensus, chaque noeud produit un engagement : une courte valeur qui représente l'intégralité de l'état. Dans Ethereum aujourd'hui, c'est un hash de 32 octets. Cet engagement va dans le block header. Si le vôtre ne correspond pas, votre état a divergé du réseau. Cela crée deux exigences clés qu'un mapping clé-valeur plat ne peut pas satisfaire. Pour calculer un engagement à partir d'un mapping plat, il faudrait sérialiser toutes les entrées dans un ordre déterministe et les hasher ensemble. Et donc, chaque fois qu'on modifie un solde, on re-sérialise et re-hashe l'intégralité de l'état. C'est un travail en O(n) par bloc sur plus de 250 Go de données. Un arbre résout ce problème. Le hash de chaque noeud est calculé à partir des hashs de ses enfants. On modifie une feuille, et seuls les hashs le long du chemin vers la racine doivent être recalculés. Soit O(log n) opérations au lieu de O(n). Alice veut vérifier son solde sans faire confiance à personne. Elle ne peut pas stocker 250+ Go d'état. Avec un store clé-valeur plat, la seule façon de vérifier une valeur est de recalculer l'engagement soi-même, ce qui nécessite de disposer de l'intégralité de l'état. Un arbre résout aussi ce problème. Pour prouver qu'une valeur existe, le prouveur fournit le chemin de cette feuille jusqu'à la racine, plus suffisamment d'informations (une preuve) à chaque niveau pour recalculer les hashs. Alice (la vérificatrice) peut alors reconstruire le hash racine à partir de cette petite preuve et le comparer à la racine connue. Nous avons établi que nous avons un store clé-valeur (adresses → comptes) à organiser en arbre. Comment ? En utilisant un trie (prononcé "traï", de retrieval). Un trie utilise la clé elle-même comme chemin à travers l'arbre. Chaque caractère de la clé détermine quelle branche suivre. Pour une clé hexadécimale comme Ethereum utilise un trie hexaire : un enfant par chiffre hexadécimal (0-F), donnant une largeur maximale de 16. La profondeur dépend de la longueur de la clé. Avant insertion, chaque adresse est hashée avec keccak256, produisant une clé de 32 octets (64 chiffres hexadécimaux).2 Les clés de stockage des contrats sont hashées de la même manière. Les deux tries ont une profondeur maximale de 64. La variante Patricia utilisée par Ethereum compresse le trie en fusionnant les noeuds de branchement n'ayant qu'un seul enfant en un noeud d'extension (en violet dans la figure ci-dessus). La structure du trie est en place. On est maintenant prêts à ajouter la partie Merkle. Dans un Patricia trie simple, chaque noeud représente un chiffre hexadécimal de la clé. Dans un Merkle trie, chaque noeud possède aussi un hash calculé à partir des hashs de ses enfants. On modifie une feuille, et chaque noeud sur le chemin vers la racine obtient un nouveau hash. Comment le hash de chaque noeud est-il calculé ? Pour un noeud de branchement, on combine les références à tous ses enfants et on hashe le résultat avec keccak256. Le résultat est un seul hash de 32 octets. Le hash racine engage l'intégralité de l'état, et il est inclus dans chaque block header. N'importe quel validateur peut calculer le state root après avoir exécuté les transactions d'un bloc et vérifier qu'il correspond. Et puisque seul le chemin d'une feuille modifiée jusqu'à la racine nécessite un recalcul des hashs, on obtient les mises à jour en O(log n) promises plus haut — un engagement efficace. Sur quelle propriété cela repose-t-il ? La résistance aux collisions : il est calculatoirement infaisable de trouver deux états distincts produisant la même racine keccak256. Le hash racine identifie l'état de manière unique. L'implémentation réelle d'Ethereum est plus complexe : l'encodage RLP pour sérialiser les noeuds avant le hachage, des spécifications de tableaux différentes selon les types de noeuds (branchement, feuille et extension), des flags pour les longueurs de chemin paires/impaires. Les noeuds du trie sont stockés dans une base de données clé-valeur (historiquement LevelDB, bien que les clients varient désormais). Chaque clé est le hash keccak256 du contenu du noeud encodé en RLP ; chaque valeur est le noeud lui-même. Les trois types de noeuds : Pour rechercher une clé, on part du hash racine (dans le block header), on récupère le noeud racine, on suit l'enfant approprié en fonction du prochain chiffre hexadécimal, et on répète. Chaque niveau est une lecture disque aléatoire. La documentation Ethereum couvre cela en détail. Nous avons affirmé plus tôt qu'un arbre permet des preuves partielles : vérifier une seule valeur sans disposer de l'état complet. Voici comment. Alice veut vérifier son solde Ethereum depuis le wallet de son téléphone. L'état complet fait 250+ Go ; elle ne peut pas le stocker. Son wallet pourrait interroger un fournisseur de noeuds tiers comme Infura ou Alchemy en coulisses, mais ce fournisseur pourrait être compromis, mentir, ou avoir été piraté. Elle n'aurait aucun moyen de le savoir. La structure de Merkle offre une alternative. Alice (la vérificatrice) ne stocke que les block headers (quelques Ko chacun). Elle demande à n'importe quel full node (le prouveur) son solde plus une preuve. Elle recalcule la racine à partir de la preuve. Si elle correspond au state root dans le header, le solde est correct, garanti mathématiquement. Considérons un trie de profondeur $d$ et un chemin $k = (k_0, k_1, \ldots, k_{d-1})$ où chaque $k_i$ est un chiffre hexadécimal de la clé hashée du compte. Pour prouver la valeur à ce chemin, le prouveur fournit : La vérification reconstruit la racine de bas en haut. On hashe la feuille, puis on remonte l'arbre en combinant avec les frères à chaque niveau : $$H_d = \text{hash}(v)$$ $$H_{i-1} = \text{hash}(h_{i,0} | h_{i,1} | \cdots | h_{i,15})$$ $$\text{où } h_{i,j} = \left\lbrace \begin{array}{ll} H_i & \text{si } j = k_{i-1} \\ S_i[j] & \text{sinon} \end{array} \right.$$ Si $H_0$ correspond au state root, la preuve est valide. Le prouveur doit fournir le compte complet (si un champ était erroné, le hash de la feuille serait différent et la preuve échouerait), mais le vérificateur ne voit jamais le reste de l'état ; uniquement les hashs des noeuds frères le long du chemin : Supposons que le hachage de l'adresse d'Alice produise une clé commençant par Qu'en est-il des valeurs dans le stockage des contrats ? Rappelons que chaque compte possède un Alice peut vérifier une seule valeur d'état avec une preuve de Merkle. Les validateurs font quelque chose de similaire des milliers de fois par bloc : lire l'état, exécuter les transactions, calculer un nouveau state root. L'engagement fondamental d'Ethereum est la décentralisation. Comme Vitalik Buterin l'a formulé : "Sur le long terme, le plan est de maintenir des noeuds Ethereum entièrement vérifiés qu'on pourrait littéralement faire tourner sur son téléphone." La validation devrait être accessible sur du matériel ordinaire, pas uniquement dans des data centers. Actuellement, le world state croît d'environ un gigaoctet par semaine. À mesure qu'il grossit, une part moindre du trie tient en mémoire, et davantage de recherches nécessitent des lectures disque aléatoires. Comme je l'ai abordé dans un article précédent, accéder aux données sur disque peut créer des goulots d'étranglement. Pour respecter la contrainte de slot de 12 secondes d'Ethereum, les validateurs ont besoin de stockage plus rapide (des SSD au minimum, de plus en plus de classe NVMe), ce qui fait grimper les coûts et va à l'encontre de l'objectif de décentralisation. Et si les validateurs ne stockaient pas du tout l'état ? Au lieu de lire depuis le disque, ils pourraient recevoir des preuves pour chaque valeur touchée par un bloc. La même astuce qu'Alice a utilisée, à grande échelle. Le problème est la taille des preuves. Chaque preuve requiert les hashs des noeuds frères à chaque niveau : 15 frères × 64 niveaux × 32 octets ≈ 30 Ko dans le pire cas, environ 3 Ko en moyenne. Avec les blocs actuels utilisant environ 30M de gas et les lectures d'état cold coûtant 2100 gas chacune,3 un bloc touche facilement des milliers de valeurs. À environ 3 Ko en moyenne, cela représente plusieurs Mo de bande passante supplémentaire par bloc. 10 Mo incrémentaux par bloc représenteraient plus de 2 To/mois de bande passante supplémentaire par validateur : le genre de surcharge qui pousse les stakers individuels vers les data centers. La taille des preuves est donc une contrainte bloquante. En réduisant les preuves, la validation sans état devient viable. Une approche pour réduire les preuves : remplacer les engagements basés sur les hashs par des engagements polynomiaux. C'est exactement ce que font les Verkle trees, réduisant les preuves de plusieurs Ko à moins de 150 octets chacune. L'arbre d'état d'Ethereum prend en réalité une autre direction (un trie binaire avec des engagements basés sur des hashs résistants au quantique), mais la cryptographie sous-jacente reste très pertinente : les engagements polynomiaux sont le fondement des preuves à connaissance nulle, un domaine en plein essor dont les applications parcourent toute la feuille de route de mise à l'échelle d'Ethereum et bien au-delà. La Partie 2 explique le fonctionnement des Verkle trees, en s'appuyant sur les corps finis et les courbes elliptiques. La croissance de l'état pose un autre problème : la validation sans état peut dispenser les validateurs de stocker l'état, mais l'état complet doit tout de même exister quelque part pour construire les blocs. De nouvelles primitives de stockage comme le stockage expirant et les enregistrements de type UTXO sont actuellement en discussion et pourraient empêcher ces 250+ Go de croître indéfiniment. On pourrait en réduisant la largeur de l'arbre, mais dans l'architecture actuelle les compromis sont lourds. Chaque niveau de traversée du trie est une lecture disque aléatoire : le noeud racine pointe vers un enfant à un emplacement, qui pointe vers un autre enfant ailleurs. Un trie hexaire avec une profondeur effective d'environ 8-10 signifie 8-10 lectures aléatoires par recherche. Un trie binaire aurait une profondeur d'environ 30-40. Même sur NVMe, les lectures aléatoires coûtent des dizaines de microsecondes chacune. Multipliez par des milliers d'accès d'état par bloc, et passer en binaire ferait exploser le temps de slot de 12 secondes. Le branchement hexaire était un choix naturel pour les clés encodées en hexadécimal, tout en gardant le trie suffisamment peu profond pour des recherches rapides. Et le gain n'est même pas si intéressant. Un trie binaire ne nécessite qu'un seul hash de noeud frère par niveau au lieu de 15, mais il est 4× plus profond (puisque $\log_2 n = 4 \log_{16} n$). Effet net : 15× moins de frères par niveau, 4× plus de niveaux, donc les preuves se réduisent d'environ 15/4 ≈ 4×. Si les preuves hexaires font environ 10 Mo par bloc, le binaire ramène à environ 2,5 Mo... toujours une surcharge réseau significative. Avec la validation sans état, où les validateurs vérifient des preuves au lieu de parcourir le trie, la profondeur cesse d'être un goulot d'étranglement, mais la surcharge liée à la taille des preuves demeure. Les autres tokens comme USDC sont suivis dans le stockage des contrats. ↩ keccak256 est la fonction de hachage d'Ethereum ; la version pré-standardisation de ce qui est devenu SHA-3. Le hachage empêche les attaquants de fabriquer des adresses qui créeraient des branches pathologiquement déséquilibrées. ↩ EIP-2929 distingue les lectures cold (premier accès, 2100 gas) des lectures warm (accès suivants, 100 gas). Utiliser le coût cold ici sous-estime le nombre total d'accès. ↩
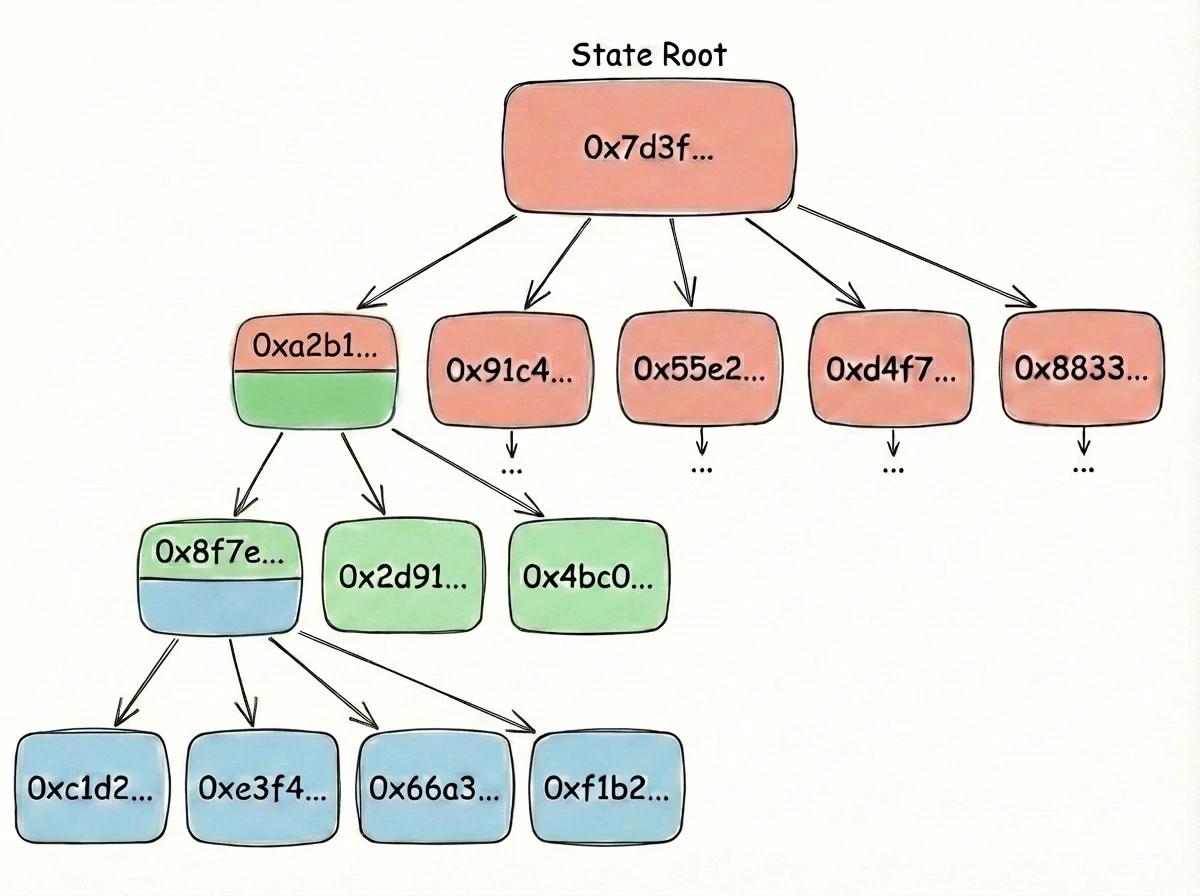
Le World State
storageRoot. Le code est stocké on-chain mais en dehors du world state, référencé par codeHash. Nous reviendrons sur ce stockage imbriqué quand nous aborderons les preuves de Merkle.Pourquoi un arbre ?
1. Engagement efficace
2. Preuves partielles
Tries : les clés comme chemins
4a7f..., on part de la racine, on prend la branche 4, puis a, puis 7, puis f, et ainsi de suite jusqu'à atteindre la valeur stockée. On ne stocke pas les clés explicitement ; le chemin est la clé.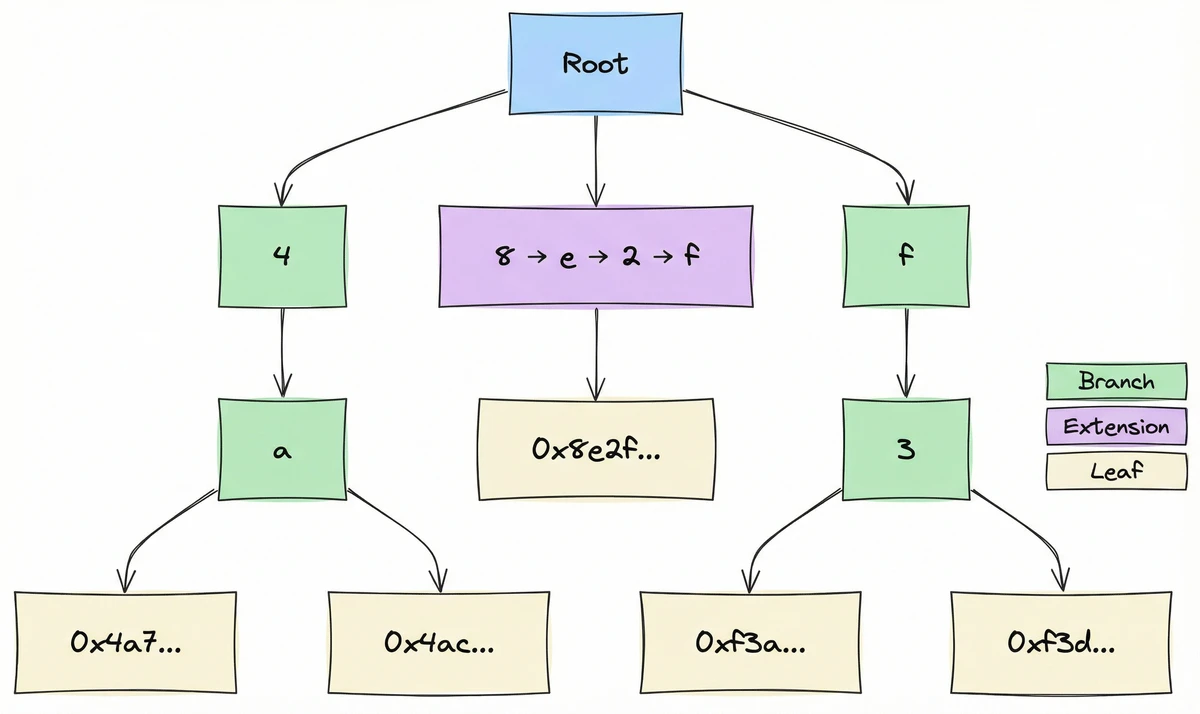
Merkle Patricia Tries
En savoir plus sur l'implémentation
[v0, v1, ..., v15, vt]. Chaque vi pointe vers un enfant pour le chiffre hexadécimal i (ou vide). vt contient une valeur si une clé se termine ici.[encodedPath, value]. Le chemin encode les nibbles restants de la clé ; la valeur correspond aux données du compte.[encodedPath, nextNode]. Compresse les chaînes de noeuds de branchement à enfant unique en un seul noeud (l'optimisation Patricia).Preuves de Merkle
Preuve et vérification
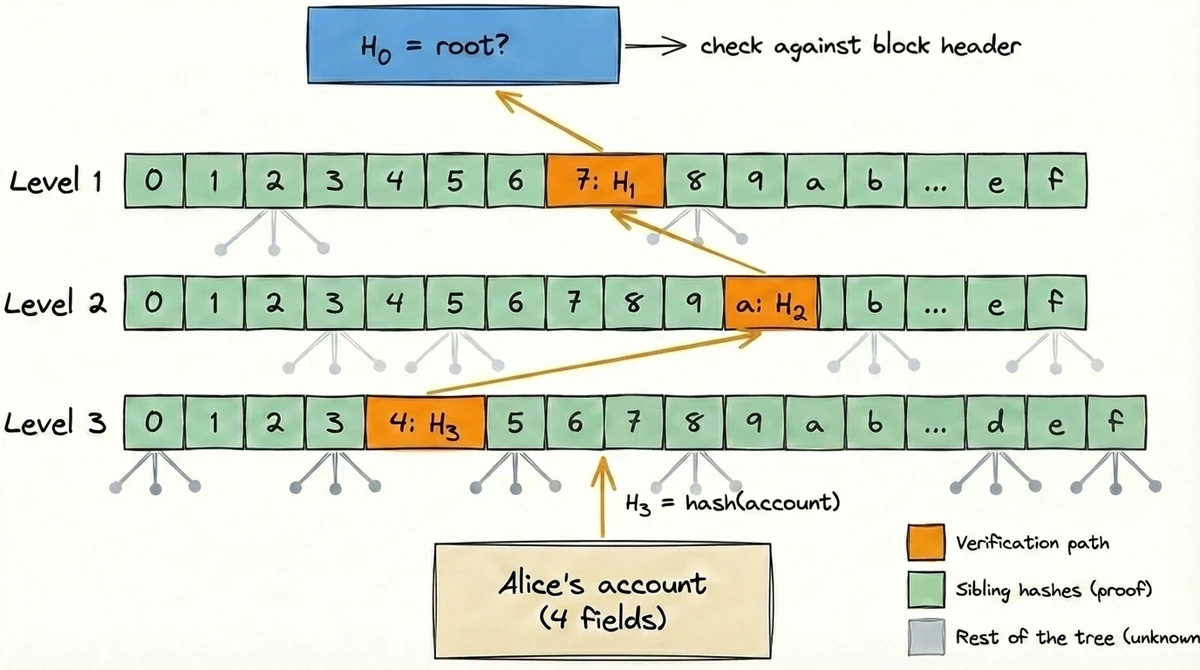
Exemple pas à pas
7a4.... Dans un trie simplifié à 3 niveaux, le chemin est $k = (7, a, 4)$. La preuve contient les données du compte d'Alice plus jusqu'à 45 hashs de noeuds frères (15 à chacun des 3 niveaux). La vérification se fait de bas en haut :4 parmi ses frères, hasher les 16 → $H_2$a parmi ses frères, hasher les 16 → $H_1$7 parmi ses frères, hasher les 16 → $H_0$storageRoot, la racine d'un autre trie contenant le stockage de ce contrat. Pour prouver une valeur de stockage, on fournit deux preuves : une du state root jusqu'au compte (qui inclut storageRoot), et une autre du storageRoot jusqu'au slot de stockage. La même logique de vérification s'applique, simplement imbriquée.Preuves plus petites, possibilités plus grandes
Et ensuite
Annexe
Pourrait-on réduire les preuves de Merkle en modifiant la forme de l'arbre ?
Cet article a été écrit en collaboration avec Claude.