Quand Parquet supplante CSV
La réalité physique qui rend la disposition des fichiers déterminante En décembre 2021, je dirigeais une nouvelle équipe chez Amazon, chargée de construire une application d'analyse de tendances. Nos données arrivaient dans S3 sous forme de fichiers CSV, étaient ingérées dans une base de données, puis alimentaient des traitements batch hebdomadaires. Un ingénieur data a proposé de passer du format CSV à Parquet. Un débat s'en est suivi. Parquet a gagné. Je l'avoue : je n'ai jamais vraiment compris pourquoi. Quand j'ai demandé des explications, on m'a dit que le stockage en colonnes offrait de meilleures performances, une meilleure compression, et ainsi de suite. Ça semblait presque trop beau pour être vrai. Je n'avais pas une compréhension solide des compromis, encore moins des mécanismes derrière ces avantages. C'était mes premiers 90 jours dans ce rôle, alors j'ai fait comme beaucoup de managers : j'ai suivi mon instinct et je suis passé à autre chose. Cet article est ma tentative de finalement comprendre. Sur disque, les données d'un fichier sont stockées comme une séquence contiguë d'octets :1 $[b_0, b_1, b_2, \ldots, b_n]$ où chaque $b_i$ est un octet (8 bits, chacun 0 ou 1) et $n$ se compte typiquement en millions (Mo) voire milliards (Go) pour les traitements analytiques. Les requêtes analytiques ont rarement besoin de toutes ces données. Une requête typique pourrait agréger une colonne, filtrer sur une autre, et ignorer le reste. Si un fichier a 100 colonnes et 10 millions de lignes, mais que la requête ne touche que 3 colonnes, lire le fichier entier signifie transférer 30 fois plus d'octets que nécessaire. À grande échelle—des centaines de fichiers de plusieurs gigaoctets chacun—cette surcharge domine. Lire des fichiers entiers n'est pas viable. Il faut donc être chirurgical : extraire uniquement les octets dont on a réellement besoin. Deux opérations permettent de faire cela : La disposition du fichier détermine si les données dont on a besoin sont contiguës (un seul seek) ou dispersées (de nombreux seeks). Mais il y a une contrainte : le seek est coûteux par rapport au read. Un disque dur traditionnel a une latence d'accès d'environ 10 ms (le seek) et un débit de 150 Mo/s (le read). Comparons : Passer de 10 octets à 1 Mo (100 000 fois plus de données) ne double même pas le temps d'E/S si les données lues sont contiguës. L'objectif est clair : minimiser les seeks, maximiser les octets par seek. La stratégie qui permet d'y parvenir s'appelle le batching : lire de gros blocs contigus au lieu de nombreuses petites lectures dispersées dans le fichier. Le même principe s'applique au stockage objet cloud comme S3. Les disques d'AWS ont toujours une surcharge de seek, mais de notre point de vue le goulot d'étranglement est la surcharge des requêtes HTTP (TCP, TLS, aller-retour). Le batching ici signifie demander de grandes plages d'octets par requête HTTP. Contrairement au disque (une seule tête de lecture), S3 permet d'émettre plusieurs requêtes en parallèle, mais la concurrence est limitée donc l'objectif reste le même : moins de requêtes avec des plages d'octets plus grandes. Les données analytiques sont typiquement tabulaires : lignes et colonnes. Quand on sérialise une table en séquence d'octets, il y a deux choix naturels. Considérons une simple table d'employés : Orienté ligne (CSV) : stocker chaque ligne de manière contiguë, puis la ligne suivante. Orienté colonne (Parquet) : stocker chaque colonne de manière contiguë, puis la colonne suivante. Cela change quels octets on doit lire. Considérons Avec CSV, les colonnes sont entrelacées dans chaque ligne. On pourrait lire le fichier entier et ignorer ce dont on n'a pas besoin, mais on vient d'établir que ce n'est pas viable à grande échelle. Et si on avait un index indiquant exactement où commence chaque champ ? Pourrait-on alors se positionner directement sur name et salary et ne lire que ceux-là ? On pourrait, mais ça n'aiderait pas. Pour lire 2 colonnes sur 1 million de lignes, il faudrait 2 millions de seeks séparés (un par champ). À 10 ms par seek sur HDD, c'est plus de 5 heures de temps de seek seul. Le problème n'est pas de savoir où sont les données. Le problème est que les données dont on a besoin sont dispersées. La disposition orientée ligne force soit à tout lire, soit à faire des millions de petites lectures. Aucune de ces options n'est acceptable. La disposition en colonnes résout ce problème. Chaque colonne est stockée de manière contiguë, donc lire name et salary signifie deux seeks et deux lectures séquentielles. Les données dont on a besoin sont physiquement regroupées. Il suffit d'avoir un moyen de localiser où commence chaque colonne. C'est ce que Parquet fournit. Un fichier Parquet a trois composants clés : Sous forme de séquence d'octets : Les row groups (~128 Mo chacun) sont des partitions horizontales de lignes. Ils permettent le traitement parallèle : les moteurs de requêtes distribués comme Spark ou BigQuery peuvent assigner différents row groups à différents workers. Les column chunks résident dans chaque row group. Les données de chaque colonne sont stockées de manière contiguë. C'est là qu'opère réellement le stockage en colonnes. Les column chunks sont ensuite divisés en pages (~1 Mo chacune), où l'encodage et la compression sont appliqués. On n'entrera pas dans le détail des pages ici. Le footer est stocké à la fin du fichier et contient les métadonnées nécessaires pour lire chirurgicalement : l'offset (où se positionner), la taille (combien lire), et les statistiques (min/max/nulls) pour chaque column chunk de chaque row group. Voici à quoi ressemble le footer (simplifié) : Pour lire un fichier Parquet, on commence par se positionner à la fin, lire le footer, puis l'utiliser pour localiser exactement les données dont on a besoin. Cette structure permet trois avantages clés : l'efficacité de projection (ne lire que les colonnes nécessaires), la compression (les column chunks contiennent des données homogènes), et le predicate pushdown (sauter des row groups entiers selon les statistiques). Il y a d'autres avantages—le parallélisme grâce aux row groups et la sécurité des types grâce au schéma—mais ces trois-là expliquent l'essentiel de la supériorité de Parquet pour l'analytique. Passons aux chiffres. Considérons 1 million d'enregistrements d'employés avec 4 colonnes totalisant ~100 Mo. La requête En utilisant le footer de notre exemple précédent : name est à l'offset 0 (2,1 Mo), salary est à l'offset 2,5 Mo (0,8 Mo). Deux seeks, 2,9 Mo transférés. Sur HDD, c'est environ 40 ms au total. On saute 97 % du fichier. Moins d'octets signifie des E/S encore plus rapides. Les colonnes effectivement lues peuvent être rendues plus compactes encore. Dans chaque column chunk, toutes les valeurs partagent le même type, et en pratique elles suivent souvent des motifs : catégories répétées, timestamps séquentiels, clés triées. Parquet exploite ces motifs via l'encodage : des transformations propres à chaque colonne, appliquées au niveau des pages. L'encodage par dictionnaire pour les chaînes de caractères à faible cardinalité (peu de valeurs uniques). Considérons 8 noms de départements répétés sur 1 million de lignes. Au lieu de stocker « Engineering » 200 000 fois (~12 octets chacun), on construit un dictionnaire associant chaque valeur unique à un petit entier : L'encodage delta pour les entiers séquentiels. Les timestamps s'incrémentent souvent de petites quantités : L'encodage par plages (RLE) pour les valeurs répétées consécutives. Si les données sont triées, on obtient de longues séquences :3 Après l'encodage, une compression générique (Snappy, Zstd ou autres) est appliquée au résultat pour un gain supplémentaire. Les deux bénéficient de la disposition en colonnes : regrouper les valeurs par colonne expose des motifs qui réduisent la taille du fichier. Le predicate pushdown permet de sauter des row groups entiers sans les lire. Un prédicat est une condition qui filtre les lignes : la clause Requête : Si 2 des 10 row groups survivent, on a éliminé 80 % des E/S avant de lire la moindre donnée réelle. Cela fonctionne aussi pour les strings. Min/max utilisent l'ordre alphabétique, donc si un row group a min="Aaron" et max="Cynthia", une requête pour Pour les colonnes à haute cardinalité comme Parquet optimise pour les lectures analytiques : beaucoup de lignes, peu de colonnes. Les coûts apparaissent à deux endroits : Les écritures sont coûteuses et inflexibles. Créer un fichier Parquet nécessite de mettre en mémoire tampon un row group entier (~128 Mo), calculer les statistiques pour chaque column chunk, appliquer l'encodage et compresser. CSV, c'est juste concaténer des strings. Et les fichiers Parquet sont immuables : on ne peut pas ajouter de lignes sans réécrire le fichier (le footer serait invalidé). Avec CSV, Toutes les lectures n'en bénéficient pas. Les lectures ponctuelles sont terribles : même avec le predicate pushdown, on lit des column chunks entiers (des mégaoctets) pour récupérer une ligne. Les bases de données orientées ligne utilisent des index pour un accès O(log n) à un enregistrement. Et plus on sélectionne de colonnes, moins on gagne. Si la charge de travail est transactionnelle (beaucoup de lectures et écritures d'enregistrements individuels), Parquet est le mauvais choix. Le format choisi doit correspondre à la charge de travail : De nombreux systèmes utilisent les deux. Postgres pour l'application en production, fichiers Parquet (ou un entrepôt de données orienté colonnes comme BigQuery) pour le reporting. Ils servent des objectifs différents. Parquet a tellement dominé la catégorie de l'analytique en colonnes que l'innovation s'est déplacée vers des espaces adjacents : Arrow pour le traitement en mémoire, les lakehouses (Delta Lake, Iceberg, Hudi) pour les transactions et les ajouts par-dessus des fichiers immuables. Le principe sous-jacent est l'asymétrie de latence d'accès : que ce soit les seeks disque ou les allers-retours HTTP, le coût de démarrer une lecture domine le coût de la poursuivre. Organisez les données pour que les octets nécessaires soient contigus, et le tour est joué. Une simplification : les fichiers peuvent être fragmentés sur des blocs disque non contigus, et les systèmes de fichiers ajoutent des couches d'abstraction. Le modèle mental reste valide pour comprendre les compromis de disposition. ↩ Les SSD éliminent les seeks mécaniques et sont plus tolérants, mais le principe reste : peu de grandes lectures séquentielles battent beaucoup de petites lectures. ↩ Parquet ne trie pas les données. Il faut trier avant l'écriture. La clé de tri principale bénéficie le plus ; les clés secondaires bénéficient moins, et seulement si elles sont de faible cardinalité. ↩
Les fichiers comme tableaux d'octets
Stockage Latence d'accès Débit Implication HDD ~10 ms (seek mécanique) 150 Mo/s La latence domine ; le batching est essentiel SSD2 ~0,1 ms (pas de pièces mobiles) 500–3000 Mo/s Pénalité plus faible par seek ; le batching reste gagnant S3 ~100 ms (aller-retour HTTP) 100+ Mo/s Privilégier les grandes plages d'octets ; paralléliser entre chunks Orientation ligne vs colonne
name age salary dept Alice 32 95000 Eng Bob 28 72000 Mkt Carol 45 120000 Eng [Alice,32,95000,Eng][Bob,28,72000,Mkt][Carol,45,120000,Eng][Alice,Bob,Carol][32,28,45][95000,72000,120000][Eng,Mkt,Eng]SELECT name, salary : on a besoin de 2 colonnes sur 4.Structure d'un fichier Parquet
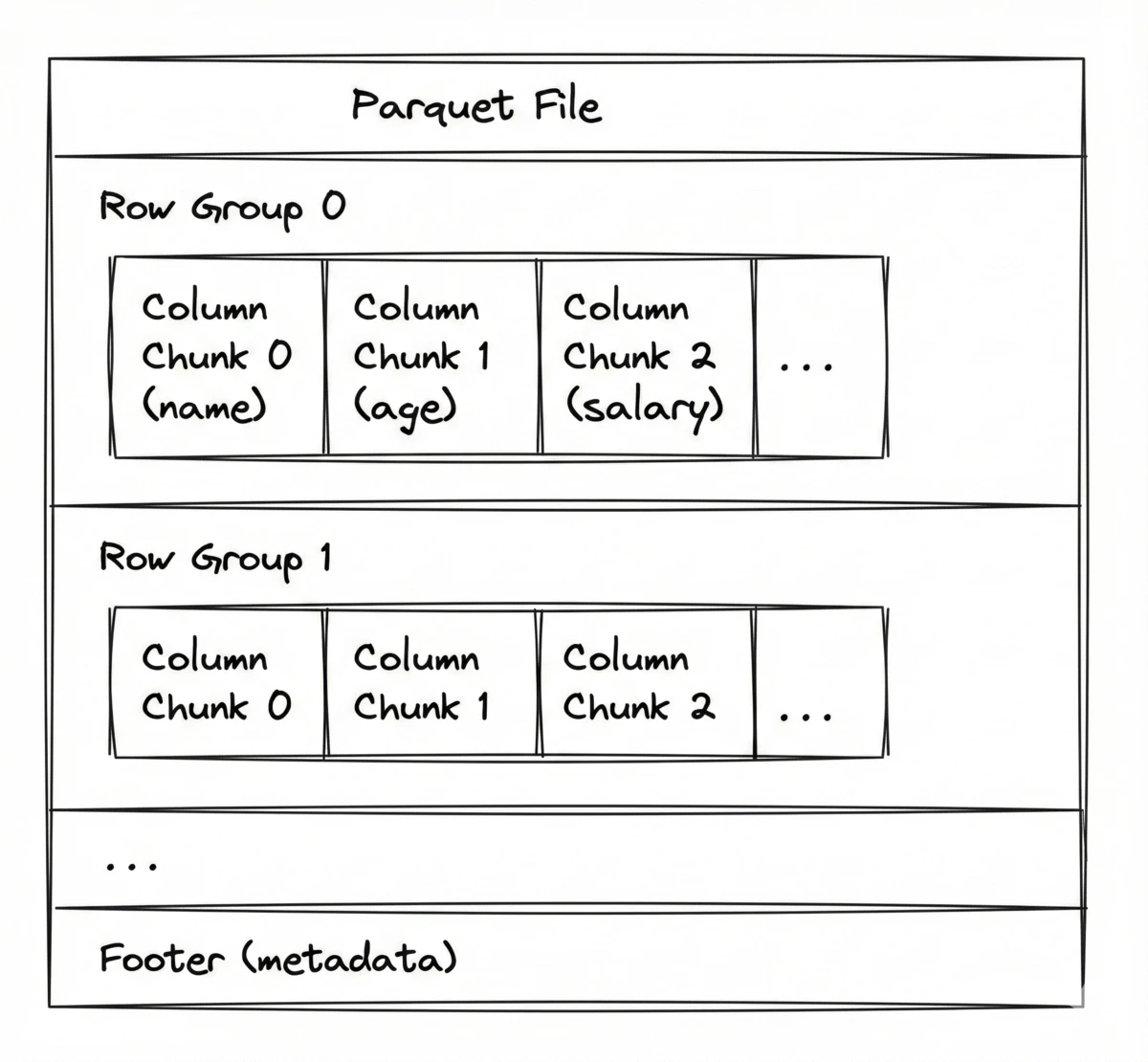
[RG0:Col0][RG0:Col1][RG0:Col2]...[RG1:Col0][RG1:Col1][RG1:Col2]...[Footer]Footer:
Schema: name (STRING), age (INT32), salary (INT64), dept (STRING)
Row Group 0 (rows 0–99,999):
name: offset=0, size=2.1MB, min="Aaron", max="Cynthia", nulls=0
age: offset=2.1MB, size=0.4MB, min=18, max=67, nulls=12
salary: offset=2.5MB, size=0.8MB, min=31000, max=185000, nulls=0
dept: offset=3.3MB, size=0.1MB, min="Design", max="Sales", nulls=0
Row Group 1 (rows 100,000–199,999):
...1. Efficacité de projection
SELECT name, salary n'a besoin que de 2 colonnes.2. Compression
{0: "Design", 1: "Engineering", ...}. Puis on stocke juste les codes entiers (1 octet chacun) au lieu des chaînes complètes. Compression d'environ 12:1.[1704067200, 1704067201, 1704067203, ...]. Au lieu de stocker chaque valeur de 8 octets, on stocke la première valeur une fois, puis juste les différences : [1704067200, +1, +2, ...]. Les deltas tiennent en 1–2 octets. Compression d'environ 4–8:1.Design, Design, ...(50k fois)..., Engineering, .... Au lieu de répéter la valeur, on la stocke une fois avec un compteur : (Design, 50000), (Engineering, 200000), .... La compression augmente avec la longueur de la séquence ; une séquence de 50 000 devient une seule paire (valeur, compteur).3. Predicate Pushdown
WHERE en SQL. Dans un plan d'exécution de requête, les opérations forment une hiérarchie—lecture des données en bas, transformation et filtrage plus haut. « Pushdown » signifie déplacer le filtre vers le bas de cette hiérarchie, du moteur de requête vers la couche de stockage. Au lieu de lire les données puis d'écarter les lignes qui ne correspondent pas, on les saute avant de les lire. Les statistiques min/max du footer rendent cela possible : Parquet peut vérifier si un row group pourrait contenir des correspondances sans lire les données réelles.SELECT name FROM employees WHERE salary > 200000name = 'Zoe' peut le sauter entièrement.Filtres de Bloom pour les colonnes à haute cardinalité
user_id, min/max est inutile (la plage couvre tout). Les filtres de Bloom offrent une alternative : un tableau de bits avec plusieurs fonctions de hachage qui répond « certainement pas ici » ou « peut-être ici ». Un faux positif (« peut-être ici » alors que la valeur n'y est pas) signifie une lecture inutile. Le taux suit $(1 - e^{-kn/m})^k$ où $k$ est le nombre de fonctions de hachage, $n$ les lignes, $m$ les bits—et il existe une formule en forme close pour le $k$ optimal qui minimise ce taux. Un sujet pour un autre article.Les compromis
echo "new,row" >> file.csv fonctionne tout simplement.SELECT * lit tout, perdant l'avantage de la projection (bien que la compression aide toujours), et paie le coût de reconstruction pour réassembler les colonnes en lignes.À retenir
Cet article a été écrit en collaboration avec Claude.