音声入力、それだけ
25ドルのインディーMacアプリがキーボードを置き換えた話。サブスクなし、音声OSも不要。 macOSでの音声入力を試し始めたのは去年の夏だった。Apple純正の音声入力にはしばらく不満があり、ChatGPTのアプリ内版を使ってみて、基盤となる技術がAppleの提供するものよりはるかに先を行っているのは明らかだった。数年前にAmazonで自動音声認識(Automatic Speech Recognition, ASR)のベンチマークをしたことがあり、そのときの感触ともぴったり重なる。最先端は急速に進歩しており、OS純正の音声入力は追いついていない。 そこで探し始めた。多くの人と同じく、Wispr Flowをはじめとする主要なMacの音声入力アプリを一通り試したうえで、VoiceInkに落ち着いた。1年の大半は気が向いたときに使う程度で、それで十分満足していた。1か月ほど前から状況が変わり、使用頻度が一気に上がった。今では完全に音声入力派と言い切れる。あのときVoiceInkを選んでおいて良かった。 この記事では、現在のセットアップとそれぞれの選択の背景を紹介する。そしてより大きな視点での主張も一つ。私たちはいま転換点にいて、コンピューターと対話するデフォルトの手段としてのキーボードは退場しつつある。40年のタイピングを経て、これはパーソナルコンピューティングで目撃した最も大きな変化の一つだ。 一文で言うと、キーボードショートカットを押すと、音声がマイクからVoiceInkに渡り、 話し終えた瞬間から、整えられたテキストが画面に現れるまで1〜2秒。一文を口述しても段落まるごとを口述しても、このレイテンシはほぼ一定だ(これについては次のセクションで詳しく述べる)。精度も十分高く、Geminiを通したあとに修正するのは10文に1〜2語あるかないかだ。 この組み合わせで、キーボードと音声の使用比率が逆転した。以前は書き物の約90%をキーボード、10%を音声入力でこなしていたが、今はほぼその逆だ。会話の英語はおよそ毎分150〜170語、デスクトップキーボードでの平均タイピングは毎分52語前後。およそ3倍の帯域があり、ここまで来ると一般的な文章をキーボードに戻すのは、モールス信号で意思疎通を続けると言い張るようなものに感じる。そして速さは魅力の半分でしかない。ちょっとしたこと(Slackの素早い返事、まだ形になっていない考え、二文の質問)にもタイピングは静かな認知コストを伴うが、音声入力はそれをゼロまで下げてくれる。今書いているものの少なくない部分は、以前なら頭の中に留まっていただろう。 ここ1か月ほどで、自分にとって大きく改善されたことが3つある。 まず文字起こしから。去年の夏はOllama経由で量子化したWhisperをローカルで動かしていた。プライバシーには良いが、精度が十分ではなかった。そこで同じモデルを量子化なしで動かすGroqの推論に乗り換えた。しばらくは快適だったが、そのうちGroqのレイテンシが少しずつ伸びてきて、音声入力のショートカットに手を伸ばす頻度が減ってきた。その後いくつかのサービスを試し、昨年末にリリースされたElevenLabsのScribe v2 Realtimeに落ち着いた。 Scribe v2 Realtimeでの大きな飛躍は、精度というより(こちらもわずかに良くなってはいる)、初めて使ったストリーミングアーキテクチャのほうにあった。ファイルが閉じるのを待ってから処理を始めるのではなく、まだ話している最中に音声を文字起こししていく。ファイルベースのASRでは、エンドツーエンドのレイテンシは 2つ目はエンハンスメント(enhancement)。VoiceInkが生のトランスクリプトに対して走らせる二度目のパスで、言い淀みを整理し、言い回しを滑らかにし、カスタムプロンプトを適用する(これも後で取り上げる)。ここで落ち着いたモデルはGemini 3.1 Flash-Lite、Googleの現行ラインアップで最も安く、最も速いティアだ。複数の節からなるプロンプトを追える程度には賢く、平均で1〜1.5秒ほど上乗せする。精度とレイテンシの曲線上で、自分にとってのスイートスポットに合致する。 3つ目はマイクのアップグレード。現代の音声認識モデルは劣化した音声にも耐えるよう作られている(電話越しのユースケースを思い浮かべればよい)が、精度の低下が完全にゼロになることはない。入力をきれいにするために約100ドル払う余裕があれば、払う価値はある(Zoomの相手にも感謝されるはずだ)。数週間前、古いSony XM3ヘッドフォンに内蔵されたマイクからSennheiser Profile USBのカーディオイドコンデンサーマイクに切り替えたところ、出力品質が目に見えて向上した。 知る限り、VoiceInkはPrakash Joshi Paxという一人の開発者によるmacOSアプリだ。マーケティングはほとんどやっておらず、自分も普通に、あれこれ調べてClaudeに聞きながらたどり着いた。ソースコードはGitHubにありGPL v3で公開されているので、クローンしてビルドすれば無料で使える。有料ライセンスはMac 1台で25ドル(複数Mac向けのティアなら49ドル)、開発者に直接支払われる。アプリは2週間に一度ほどのペースで更新されており、自分に必要な機能はすでにそろっている(カスタム辞書、異なるカスタムプロンプトに振り分けるトリガーワード、音声区間検出など)。BYOK方式でもあり、使うモデルのAPIキーは自分で用意する。有料版を使っているのは更新を受け取りたいからでもあるし、この仕事を支援しないのは何か違うと感じるからでもある。 最初に惹かれたのは価格モデルだ。一度きりの支払いで、サブスクリプションなし。数年前のDHHのOnce哲学に共感していたし、この領域でサブスクリプションが正当化できるとは思えない。基盤となるモデルは四半期ごとに性能が上がり、価格が下がっている。その上に乗っかるインターフェースに継続課金しておきながら、しかも使うモデルの選択をユーザーから奪うというのは、勘定が合わない。 BYOKは追加コストと手間に聞こえるかもしれないが、実際にはどちらでもない。Geminiの請求は月10セント未満、ElevenLabsは毎日使う量で月およそ3ドル。とはいえ、鍵を自分で持つことの本当のメリットは、差し替えの自由にある。この1年だけでもVoiceInkの文字起こしプロバイダーをすでに3回切り替えた(ローカルのWhisper、次にGroq、今はElevenLabs)。直近で出てきたものにアプリが追いつくのを待たされたことは一度もない。 VoiceInkでもう一つ得られるのが、開発者に直接連絡できることだ。VoiceInkの「録音中はメディアを一時停止」機能(話している間Spotifyなどを止めて、終わったら再開する)が自分の環境で挙動がおかしかったときも、GitHubにissueを立てたらすぐに修正された。先週OpenAIのリアルタイムWhisperがリリースされたときも、VoiceInkはまだ対応していなかったので、リポジトリに別のissueを立てた。近いうちに解決されるはずだ。製品が何百万人にも使われ、複数年のロードマップと取締役会を持つ大きなチームに所有されるようになると、こういう対応速度は得にくくなる(もちろん、一人開発の体制には一人開発なりのボトルネックがあるのも確かだが)。 Wispr Flowは8100万ドルを調達して「音声オペレーティングシステム」を作ろうとしている。これは別の時間軸での別の賭けだ。とはいえ、音声入力が今実際にできていることに対して、月10〜15ドルのサブスクが、25ドルの一度きりの支払いと月数ドルのAPI料金の組み合わせに勝るところは、正直なところ見当たらない。 もっとも、この時点になると「音声入力ソフト」という呼び方は、VoiceInkにはもう括りが小さすぎる。 たとえばトリガーワード。「assistant」に紐づけたものがあり、口述がその言葉で始まると、VoiceInkはトランスクリプトを別のプロンプトに振り分け、Geminiに対して、文字起こしではなく質問に答えるよう指示する。「assistant, what is the time difference between London and Tokyo?」と話せば、答えがカーソルの位置にそのまま貼り付けられる。チャットウィンドウやコピペの往復はない。音声入力のショートカットが、そのままワンショットのLLMショートカットも兼ねる。 あるいは、ほとんどの発話を処理しているカスタムプロンプト。一行はこうだ。「口述が 'Fix my rambling,' で終わる場合、その前の部分を粗いドラフトとして扱い、言いたかったことを整えたバージョンを返してほしい。」 出力が締まりきっていないとき、「fix my rambling」を末尾に付け足せば、モデルは最初のパスを書き直し、時間をかけて自分でタイプした場合に近いものをエディタに届けてくれる。先週追加したもう一行は、「口述が 'in LaTeX,' で終わる場合、数式をLaTeXで書き、$ で囲んでほしい。」 これで「sum from i equals zero to n of x sub i, in LaTeX」と話すと、カーソル位置に あるいは多言語の入力。文字起こしモデルが、英語、フランス語、日本語のどれを話しているかを自動で判別してくれる。キーボードは1つのレイアウトしか印字できず、残り2つは指先の感覚の中だけにあるが、音声入力ならレイアウトの問題そのものを飛ばせる。 まだ完全ではない。何度もぶつかる粗い部分の一つが、自分の世界に固有の名前や略語のロングテールだ。VoiceInkにはカスタム辞書があるが、一語ずつ自分で登録していく必要がある。本当は、アプリの側が「うまく拾えなかった可能性が高い単語」に印を付けてくれて、後でまとめて確認できるとうれしい。あとはレイテンシ。1〜2秒なら十分速い、誤解しないでほしい。それでも、待ち時間そのものを意識しなくなるところまでは、まだ届いていない。 残っているレイテンシと精度のギャップはすぐに埋まると見ているし、音声入力はもっと大きなカテゴリー(Voice AI、あるいはVoice computingといったところか。まだ名前は定まっていない)の中に吸収されていくとも思う。スタック全体が、勾配を増していくカーブの上に乗っている。ここ数週間のデモを2つ挙げれば、その先がどうなりそうか少し見えてくる。OpenAIの
セットアップ
ElevenLabs Scribe v2 Realtimeで文字起こしされ、その結果が短いカスタムプロンプトとともにGemini 3.1 Flash-Liteを通り、整えられたテキストが目の前のアプリに貼り付けられる。4つのレイヤー、1つのショートカットだ。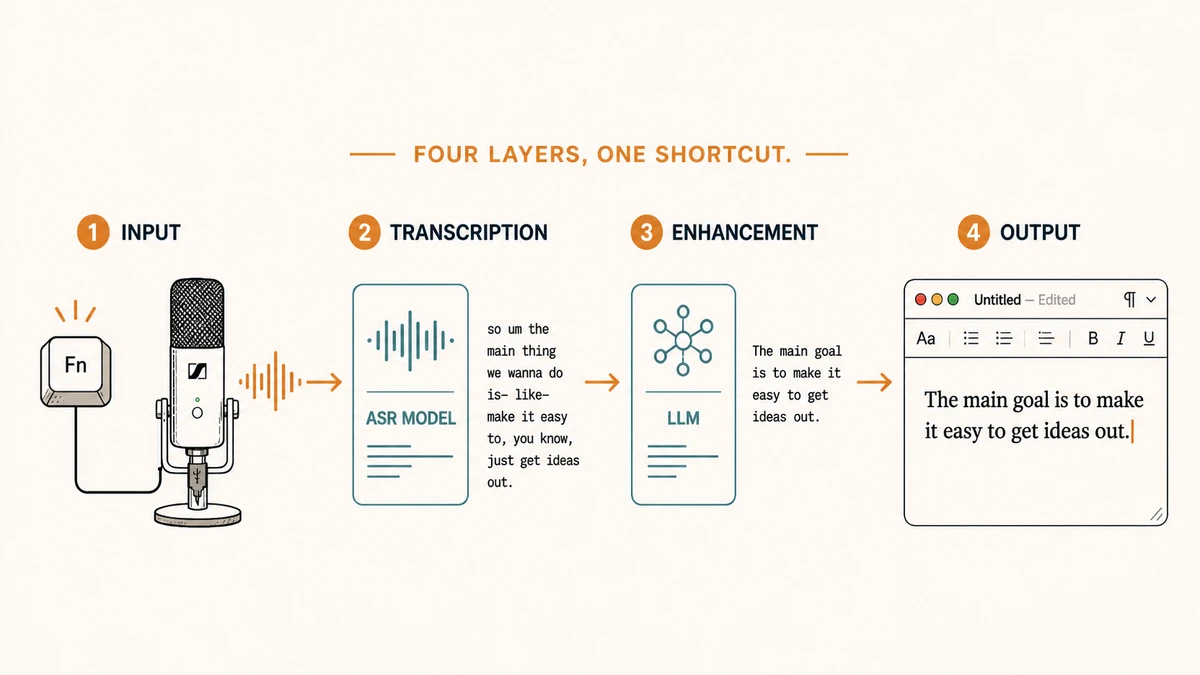
なぜ今なのか?
話すのをやめるまでの時間 + 推論時間という、2つの区間が連続する形になる。ストリーミングではそれが重なるため、話し終えた時点で作業の大半は終わっている。実際、数文ぶんの発話あたり約300ミリ秒という値が出ており、ほぼ即時に感じられる。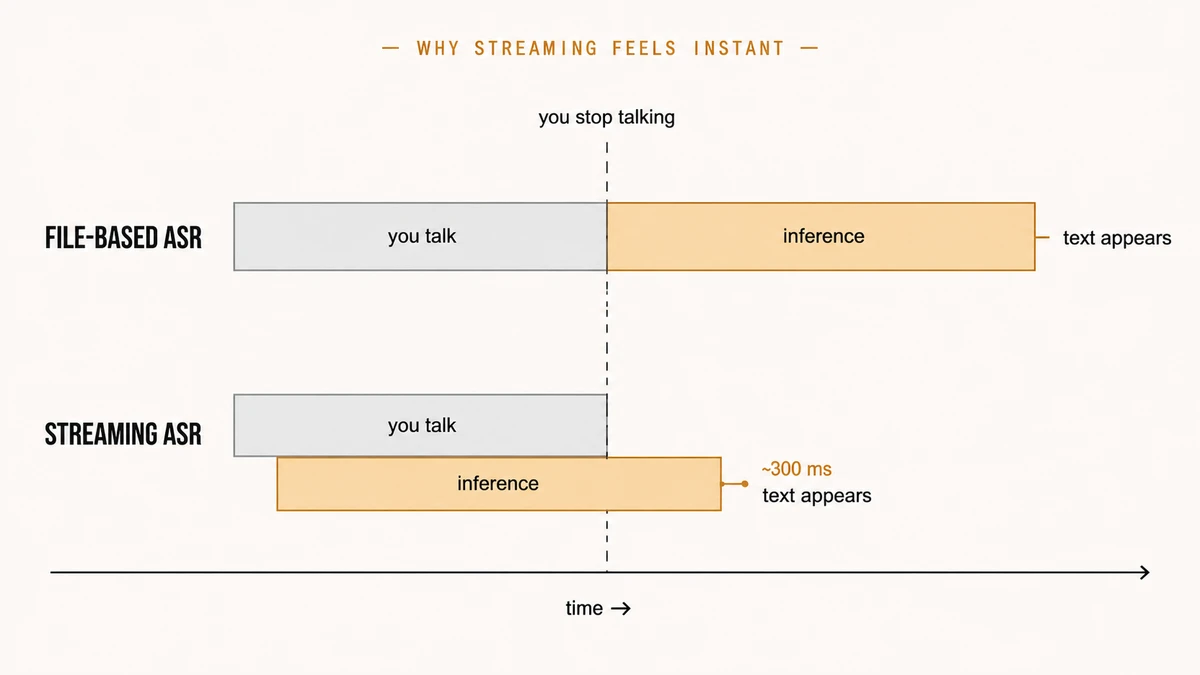
なぜVoiceInkなのか?
音声入力を超えて
$\sum_{i=0}^n x_i$が貼り付けられる。
gpt-realtime-1.5がアプリのUIを声で操作するデモ、そしてGoogle DeepMindが公開した、動きと声で操るGemini搭載のポインターだ。今のAI全般と同じで、忘れずにおきたいのは、今日使っているものはこれから先で一番ひどいバージョンだということ。そしてそれが、すでに本当に良い。
この記事はClaudeと協力して執筆しました。