ParquetがCSVに勝るとき
ファイルレイアウトが重要になる物理的な現実 2021年12月、Amazonで新しいチームを率いて、トレンド分析アプリケーションを構築していた。データはCSVファイルとしてS3に流れ込み、データベースに取り込まれ、週次バッチジョブに供給されていた。あるデータエンジニアがストレージ形式をCSVからParquetに変更することを提案した。議論が起こり、Parquetが勝った。 正直に言うと、なぜかを深く理解していなかった。理由を尋ねると、列指向ストレージはパフォーマンスが良く、圧縮も優れているなどと聞いた。うますぎる話に聞こえた。トレードオフをしっかり把握していなかったし、ましてやその利点の背後にあるメカニズムもわかっていなかった。着任してまだ90日だったので、多くのマネージャーがやるように、直感に従って先に進んだ。この記事は、ようやくそれを理解するための試みだ。 ディスク上では、ファイルのデータは連続したバイト列として格納される。1 $[b_0, b_1, b_2, \ldots, b_n]$ で、各 $b_i$ は1バイト(8ビット、各ビットは0か1)、$n$ は分析ワークロードでは数百万(MB)から数十億(GB)が一般的だ。 分析クエリがこのデータすべてを必要とすることはめったにない。典型的なクエリは1つの列を集計し、別の列でフィルタし、残りは無視する。ファイルに100列と1000万行があっても、クエリが3列しか使わないなら、ファイル全体を読み込むと必要な30倍のバイトを転送することになる。大規模になると(数百のファイル、それぞれ数ギガバイト)、このオーバーヘッドが支配的になる。ファイル全体を読むのは現実的ではない。 だから、必要なバイトだけを外科的に抽出する必要がある。 2つの操作でこれが可能になる。 ファイルのレイアウトによって、必要なデータが連続している(1回のseek)か分散している(多数のseek)かが決まる。 ただし制約がある。seekはreadに比べてコストが高い。従来のハードディスクはアクセスレイテンシが約10ms(seek)、スループットが150MB/s(read)だ。比較してみよう。 10バイトから1MB(10万倍のデータ)に増えても、読み取るデータが連続していればI/O時間は2倍にもならない。目標は明確だ。seekを最小化し、seekあたりのバイト数を最大化する。これを実現する戦略がバッチ処理だ。つまり、ファイル中に散らばった小さな読み取りを多数行う代わりに、大きな連続チャンクを読み取る。 同じ原則がS3のようなクラウドオブジェクトストレージにも当てはまる。AWSのディスクにもseekオーバーヘッドはあるが、利用者の視点からするとボトルネックはHTTPリクエストのオーバーヘッド(TCP、TLS、ラウンドトリップ)だ。ここでのバッチ処理は、HTTPリクエストごとに大きなバイト範囲を要求することを意味する。ディスク(読み取りヘッドは1つ)とは異なり、S3では複数のリクエストを並列に発行できるが、並行性には限りがあるので、目標は変わらない。より大きなバイト範囲で、より少ないリクエスト。 分析データは通常、表形式で、行と列がある。テーブルをバイト列にシリアライズするとき、自然な選択肢が2つある。簡単な従業員テーブルを考えてみよう。 行指向(CSV):各行を連続して格納し、次の行へ。 列指向(Parquet):各列を連続して格納し、次の列へ。 これにより、どのバイトを読む必要があるかが変わる。 CSVでは、列は各行内でインターリーブされている。ファイル全体を読んで不要なものを捨てることもできるが、大規模では現実的でないとさっき確認した。では、各フィールドがどこから始まるかを正確に示すインデックスがあったらどうだろう?nameとsalaryに直接seekして、それだけを読めないだろうか? できるが、意味がない。100万行から2列を読むには、200万回の個別seek(フィールドごとに1回)が必要になる。HDDで1回のseekに10msかかるとすると、seekだけで5時間以上だ。問題はデータの場所を知ることではない。問題は、必要なデータが散らばっていることだ。行指向レイアウトでは、すべてを読むか、何百万もの小さな読み取りをするか、どちらかを強いられる。どちらも現実的ではない。 列指向レイアウトはこれを解決する。各列は連続して格納されるので、nameとsalaryを読むには2回のseekと2回の順次読み取りだけでいい。必要なデータが物理的にまとまっている。あとは各列の開始位置を特定する方法があればいい。それがParquetの役割だ。 Parquetファイルには3つの主要なコンポーネントがある。 バイトシーケンスとして表すと、こうなる。 行グループ(各約128MB)は行の水平パーティションだ。これが並列処理を可能にする。つまり、SparkやBigQueryのような分散クエリエンジンは、異なる行グループを異なるワーカーに割り当てられる。 列チャンクは各行グループ内にある。各列のデータは連続して格納される。実際に列指向ストレージが実現されるのはここだ。列チャンクはさらにページ(各約1MB)に分割され、そこでエンコーディングと圧縮が適用される。ページレベルの詳細はここでは扱わない。 フッターはファイルの末尾に格納され、外科的な読み取りに必要なメタデータを含む。すべての行グループのすべての列チャンクについて、オフセット(どこにseekするか)、サイズ(どれだけ読むか)、統計情報(最小/最大/null数)が記録されている。 フッターはこんな感じだ(簡略化)。 Parquetファイルを読むには、まず末尾にseekしてフッターを読み、それを使って必要なデータの正確な位置を特定する。この構造により、3つの主要な利点が得られる。プロジェクション効率(必要な列だけを読む)、圧縮(列チャンクには同種のデータが含まれる)、述語プッシュダウン(統計情報に基づいて行グループをスキップ)だ。他にも利点はある(行グループによる並列性、スキーマによる型安全性)が、この3つが分析でParquetが勝つ理由の大半を占める。 具体的な数字で見てみよう。4列で合計約100MBの従業員レコード100万件を考える。クエリ 先ほどの例のフッターを使うと、nameはオフセット0(2.1MB)、salaryはオフセット2.5MB(0.8MB)だ。2回のseek、2.9MBの転送。HDDで合計約40ms。ファイルの97%をスキップできる。 バイト数が減れば、I/Oはさらに速くなる。実際に読む列も、より小さくできる。 各列チャンク内では、すべての値が同じ型を共有し、実際にはパターンに従うことが多い。繰り返されるカテゴリ、連続するタイムスタンプ、ソートされたキー。Parquetはこれらのパターンをエンコーディングで活用する。列の特性に合わせた変換がページレベルで適用される。 辞書エンコーディングは低カーディナリティの文字列(ユニークな値が少ない)向けだ。100万行にわたって繰り返される8つの部署名を考えてみよう。「Engineering」を20万回格納する(各約12バイト)代わりに、各ユニークな値を小さな整数にマッピングする辞書を作る。 デルタエンコーディングは連続する整数向けだ。タイムスタンプは小さな量で増加することが多い。 **ランレングスエンコーディング(RLE)**は連続して繰り返される値向けだ。データがソートされていると、長いランが得られる。3 エンコーディングの後に汎用的な圧縮(Snappy、Zstdなど)も適用され、さらにサイズが縮小される。どちらも列指向レイアウトの恩恵を受ける。値を列ごとにまとめることで、ファイルサイズの縮小につながるパターンが見えてくるからだ。 述語プッシュダウンにより、行グループ全体を読まずにスキップできる。 述語は行をフィルタする条件、SQLでいう クエリ: 10個の行グループのうち2個が生き残れば、実データを読む前にI/Oを80%削減できたことになる。 文字列でも同様だ。最小/最大はアルファベット順を使うので、行グループがmin="Aaron"、max="Cynthia"なら、 Parquetは分析的な読み取りに最適化されている。つまり、多くの行、少ない列というパターンだ。コストは2つの場所に現れる。 書き込みはコストが高く柔軟性がない。 Parquetファイルを作成するには、行グループ全体(約128MB)をメモリにバッファし、すべての列チャンクの統計情報を計算し、エンコーディングを適用して圧縮する必要がある。CSVは単に文字列を連結するだけだ。さらにParquetファイルはイミュータブルで、ファイルを書き直さずに行を追加できない(フッターが無効になる)。CSVなら、 すべての読み取りが恩恵を受けるわけではない。 単一行のルックアップは最悪だ。述語プッシュダウンがあっても、1行を取得するために列チャンク全体(メガバイト単位)を読むことになる。行指向データベースはインデックスを使ってO(log n)で単一レコードにアクセスする。また、選択する列が増えるほど利点は減る。 ワークロードがトランザクション中心(単一レコードの読み書きが多い)なら、Parquetは適さない。 選ぶフォーマットはワークロードに合わせる。 多くのシステムは両方を使う。本番アプリにはPostgres、レポーティングにはParquetファイル(またはBigQueryのような列指向ウェアハウス)といった具合だ。それぞれ目的が違う。 Parquetが列指向分析のカテゴリを制覇したため、イノベーションは隣接領域に移っている。インメモリ処理にはArrow、イミュータブルファイル上でのトランザクションと追記にはレイクハウス(Delta Lake、Iceberg、Hudi)といった形だ。 根底にある原則は、アクセスレイテンシの非対称性だ。ディスクseekであれHTTPラウンドトリップであれ、読み取りを開始するコストが継続するコストを上回る。必要なバイトが連続するようにデータを整理すれば、勝てる。
ファイルはバイト配列
ストレージ アクセスレイテンシ スループット 意味するところ HDD 約10ms(機械的seek) 150MB/s レイテンシが支配的、バッチ処理が必須 SSD2 約0.1ms(可動部なし) 500〜3000MB/s seekのペナルティは小さいが、バッチ処理は依然有利 S3 約100ms(HTTPラウンドトリップ) 100MB/s以上 リクエストごとに大きなバイト範囲、チャンク間で並列化 行指向 vs 列指向
name age salary dept Alice 32 95000 Eng Bob 28 72000 Mkt Carol 45 120000 Eng [Alice,32,95000,Eng][Bob,28,72000,Mkt][Carol,45,120000,Eng][Alice,Bob,Carol][32,28,45][95000,72000,120000][Eng,Mkt,Eng]SELECT name, salary を考えてみよう。4列中2列が必要だ。Parquetファイルの構造
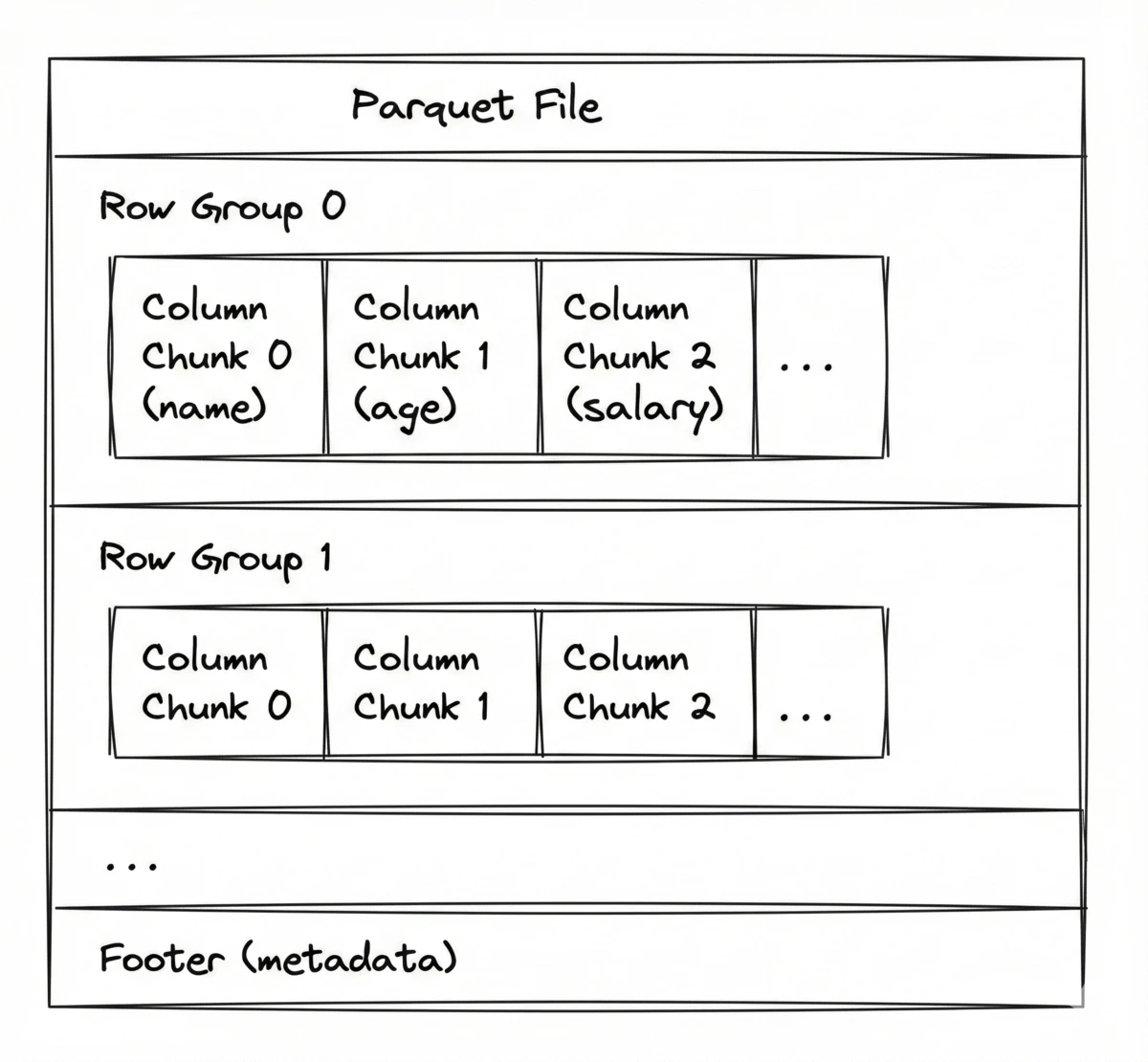
[RG0:Col0][RG0:Col1][RG0:Col2]...[RG1:Col0][RG1:Col1][RG1:Col2]...[Footer]Footer:
Schema: name (STRING), age (INT32), salary (INT64), dept (STRING)
Row Group 0 (rows 0–99,999):
name: offset=0, size=2.1MB, min="Aaron", max="Cynthia", nulls=0
age: offset=2.1MB, size=0.4MB, min=18, max=67, nulls=12
salary: offset=2.5MB, size=0.8MB, min=31000, max=185000, nulls=0
dept: offset=3.3MB, size=0.1MB, min="Design", max="Sales", nulls=0
Row Group 1 (rows 100,000–199,999):
...1. プロジェクション効率
SELECT name, salary は2列だけ必要だ。2. 圧縮
{0: "Design", 1: "Engineering", ...}。そして文字列そのものではなく整数コード(各1バイト)だけを格納する。約12:1の圧縮になる。[1704067200, 1704067201, 1704067203, ...]。各8バイト値を格納する代わりに、最初の値を一度だけ格納し、以降は差分だけを格納する。[1704067200, +1, +2, ...]。デルタは1〜2バイトに収まる。約4〜8:1の圧縮になる。Design, Design, ...(5万回)..., Engineering, ...。値を繰り返す代わりに、値を一度だけ格納してカウントを添える。(Design, 50000), (Engineering, 200000), ...。圧縮率はランの長さに比例し、5万のランは単一の(値、カウント)ペアになる。3. 述語プッシュダウン
WHERE 句だ。クエリ実行計画では、操作は階層を形成する。データの読み取りが最下層、変換とフィルタがその上だ。「プッシュダウン」とは、その階層でフィルタを下に移動させること。つまりクエリエンジンからストレージ層へ移す。データを読んでから一致しない行を捨てる代わりに、読む前にスキップする。フッターの最小/最大統計情報がこれを可能にする。Parquetは実際のデータを読まずに、行グループに一致する行が含まれうるかを確認できる。SELECT name FROM employees WHERE salary > 200000name = 'Zoe' のクエリは完全にスキップできる。高カーディナリティ列のためのBloomフィルター
user_id のような高カーディナリティの列では、最小/最大は役に立たない(範囲が全域をカバーしてしまう)。Bloomフィルターは別のアプローチを提供する。複数のハッシュ関数を持つビット配列で、「確実にここにはない」か「ここにあるかもしれない」を返す。偽陽性(「あるかもしれない」と返したが実際には値が存在しない場合)は無駄な読み取りを意味する。その率は $(1 - e^{-kn/m})^k$ に従う。$k$ はハッシュ関数の数、$n$ は行数、$m$ はビット数だ。この率を最小化する最適な $k$ の閉形式の公式が存在する。これは別の記事のテーマだ。トレードオフ
echo "new,row" >> file.csv で済む。SELECT * はすべてを読み、プロジェクションの利点を失い(圧縮は依然助けになるが)、列を行に再構築するオーバーヘッドも払う。まとめ
この記事はClaudeと協力して執筆しました。